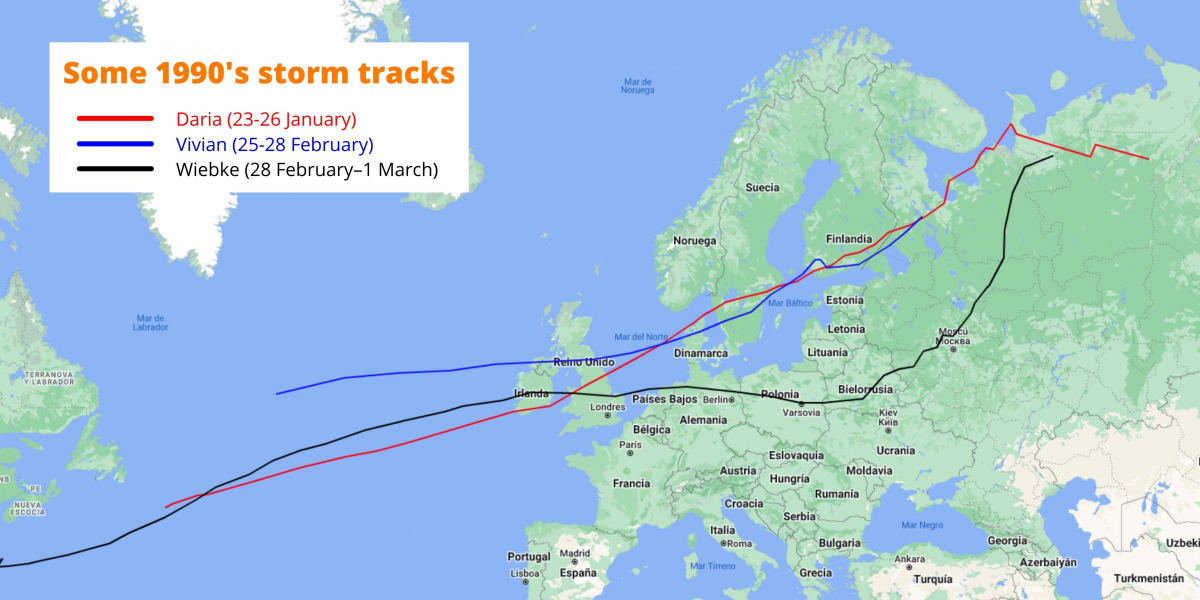
El comienzo de 1990 fue difícil para muchos lugares de Europa. Entre el 25 de enero y el 1 de marzo de 1990, ocho tormentas severas cruzaron Europa, causando pérdidas de casi 13.000 millones de euros. Dos de estas tormentas (Daria y Vivian), causaron gran parte de estas pérdidas, ya que se encuentran en el ranking de los cinco eventos más costosos de Europa desde 1970, según la reaseguradora Swiss Re. Las tormentas invernales de este tipo constituyen los riesgos naturales más costosos para Europa, ya que cada evento inflige miles de millones de euros en pérdidas por evento. De todos los peligros que han afectado a Europa desde 1970, los 5 eventos con mayores pérdidas fueron todos temporales de invierno.
Por tanto, las compañías de seguros están muy interesadas en analizar estas tormentas, ya que tienen un gran impacto en nuestra sociedad. En este post queremos hablar de la modelización de los temporales de viento, de los problemas a los que nos enfrentamos al hacerlo y del valor que aportan. Y para ello, vamos a sumergirnos en uno de los resultados del proyecto PRIMAVERA en el que participamos. Para los entendidos en detalles técnicos, podéis entrar directamente en la versión preliminar del artículo en NHESS.
Empecemos con un poco de contexto en torno a las tormentas de invierno y las compañías de seguros. En cualquier momento, las compañías de seguros en Europa están obligadas por ley a tener suficiente capital para cubrir cualquier evento que se produzca cada 200 años. Sin embargo, no disponemos de registros climáticos sistemáticos que abarquen tanto tiempo. Lo mejor que tenemos son conjuntos de datos de reanálisis, como ERA5, que se remontan "sólo" a 1950. Los reanálisis son conjuntos de datos que rellenan las lagunas de los registros meteorológicos, utilizando modelos climáticos que simulan el tiempo atmosférico. Aunque a veces son la mejor estimación de muchas variables (viento, temperatura, precipitación...), tienen algunas limitaciones, como el limitado periodo de tiempo que cubren, o el hecho de que su cálculo requiere una gran potencia de cálculo. Entonces, ¿qué opciones les quedan a los modelizadores del clima?
Aquí es donde entra el proyecto PRIMAVERA: ha desarrollado una nueva generación de modelos climáticos, bien evaluados y de alta resolución, con una cobertura global. El objetivo es que estos modelos sean útiles para los gobiernos, la sociedad en general y los distintos sectores económicos. Uno de estos sectores es, por supuesto, el de los seguros. En este trabajo, el equipo utilizó cinco modelos climáticos diferentes, que cubren el periodo comprendido entre 1950 y 2014. En conjunto, esto equivale a unos 1.300 años de datos modelizados. Esta enorme cantidad de datos fue necesaria para estudiar acontecimientos que sólo se producen cada 200 años. Los datos también fueron post-procesados, por lo que el conjunto de datos final tiene una alta resolución (0,25º por 0,25º, que es aproximadamente 27 Km, aunque varía con la latitud). Si ten interesan estos detalles de postprocesado, tienes más información en la sección de metodología al final del post.
Sin embargo, no basta con tener los datos brutos de los modelos, sino que hay que analizarlos desde el punto de vista de las aseguradoras, para identificar las tormentas de viento en el conjunto de datos. Lo que plantea cuestiones interesantes:
- ¿Cómo se detecta una tormenta en los datos de PRIMAVERA?
- ¿Cómo se define un temporal de invierno?
- ¿Y cómo se cuantifica su impacto?
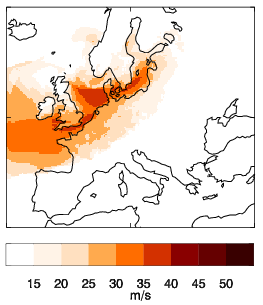
Para la primera pregunta (cómo detectar una tormenta en el conjunto de datos), los investigadores utilizaron el algoritmo TRACK. Fue publicado por Kevin Hodges en 1995 y actualizado en 1999. Una vez localizada una tormenta de viento en los datos, hay que ver cómo evoluciona en el tiempo, a qué zonas afecta y cómo. Los meteorólogos llaman a esto "huella": un diagrama que muestra cómo han evolucionado los vientos en la tormenta. Por suerte, las compañías de seguros también tienen una definición muy clara de la huella: "la máxima ráfaga de viento asociada a la tormenta durante un periodo de 72 horas". Vamos a diseccionar lo que esto significa. En primer lugar, las rachas de viento son breves aumentos de la velocidad del viento que suelen durar menos de 20 segundos. Así que, para crear un diagrama como el de arriba, que es la huella de la tormenta Daria, los meteorólogos repasan los datos de 3 días durante la tormenta, ven las rachas máximas de ese periodo y las dibujan en el mapa. Y para las rachas, se basan en la Organización Meteorológica Mundial, que define las rachas como "la velocidad media máxima del viento en 3 segundos a 10 metros de altura".
Así que parece que ya tenemos cubiertas las rachas de viento. Pero en realidad no. El problema es que los modelos climáticos no ofrecen los datos de las ráfagas de viento directamente. De los 5 modelos que el equipo de PRIMAVERA tuvo en cuenta, sólo dos de ellos ofrecen rachas máximas. Para el resto, el equipo extrajo los vientos superficiales máximos diarios y los convirtió en ráfagas mediante enfoques estadísticos. Si te interesan los detalles, dirígete a la sección de Metodología.
Con esto, el equipo de PRIMAVERA supo rastrear las tormentas de viento invernales en los datos, y generar sus huellas. Pero todo esto enmarca las cosas desde el lado del clima. ¿Qué pasa con el lado económico de las cosas? ¿Cómo se pasa del clima al impacto social?
Para estimar los daños potenciales de las tormentas de viento identificadas en los datos, los investigadores se basaron en el Índice de Pérdidas (un nombre muy original), que tiene en cuenta el área afectada por la tormenta, la densidad de población y las rachas de viento extremas en la zona.
Así, los investigadores aplicaron este Índice a los datos de los cinco modelos climáticos de PRIMAVERA, y encontraron más de 250 000 huellas de tormentas que ocurrieron en las simulaciones. De ellas, casi 70 000 causaban alguna pérdida y ~2700 de esas tormentas son severas: del tipo de tormentas que se producen aproximadamente una vez cada dos inviernos sobre Europa y que suponen el 70% de las pérdidas totales. Los resultados coinciden con los datos del clima pasado: las simulaciones de baja resolución subestiman un poco el número de tormentas por invierno, pero esto mejora con los modelos de mayor resolución. Esto confirma también uno de los principales puntos de PRIMAVERA: disponer de modelos de mayor resolución permite una mejor representación del clima.
¿Y qué es lo siguiente? En este trabajo, los investigadores han desarrollado un método sólido para seguir y reproducir las tormentas de viento invernales y cuantificar su impacto potencial. Por tanto, queda trabajo por hacer para perfeccionar el método... y ampliarlo al futuro, con las proyecciones de cambio climático de PRIMAVERA que abarcan hasta 2050. ¿Quieres saber más? Ponte en contacto directamente con el equipo de PRIMAVERA.
Metodología
En esta sección encontrará todos los detalles sobre el documento.
Los modelos PRIMAVERA utilizados para el conjunto de eventos se resumen en la siguiente tabla. Cada modelo se ejecutó tanto a una resolución estándar del tipo CMIP6 (normalmente 100 km) como a una resolución significativamente mayor (hacia 25 km). Algunos modelos utilizaron varios miembros del conjunto.
| Institución | MOHC, UREAD, NERC | EC-Earth KNMI, SHMI, BSC, CNR | CERFACS | MPI-M | CMCC |
| Nombre del modelo | HadGEM3- GC3.1 | EC-Earth3P | CNRM-CM6.1 | MPI-ESM1.2 | CMCC-CM2- (V)HR4 |
| Nombre de la resolución | LM, MM, HM | LR, HR | LR, HR | HR, XR | HR4, VHR4 |
| Resolución atmosférica nominal (CMIP6) | 250; 100; 50 | 100; 50 | 250; 50 | 100; 50 | 100; 25 |
| Número de modelos del conjunto de modelos | 5;3;3 | 2;2 | 1;1 | 1;1 | 1;1 |
Las normas del sector de los seguros prefieren cuadrículas de muy alta resolución, con una separación máxima de cuadrículas de ~25 km, aunque se prefiere menos de 10 km. Para ser coherentes con estas normas del sector, las huellas deben reducirse a una cuadrícula común. La malla objetivo fue la misma que la de las ráfagas del ERA5: 0,25°x0,25°, lo que equivale a una separación de cuadrículas de aproximadamente 18 km a 50° N. Esta referencia no es casual: facilitó el proceso de validación que se explica al final de la sección. Para lograr tanto la conversión de vientos a ráfagas como la corrección del sesgo, el equipo de PRIMAVERA utilizó el mapeo de cuantiles. El método es el siguiente:
- Las velocidades máximas de viento diarias del modelo se han reducido a la cuadrícula ERA5 mediante interpolación lineal.
- En intervalos de probabilidad del 0,5% hasta el percentil 98, el equipo calculó la función de distribución acumulativa empírica (CDF) en cada punto de la cuadrícula.
- Por encima del percentil 98, la FCD se ajusta utilizando una distribución de Pareto generalizada (GPD), que se utiliza habitualmente para ajustar las velocidades del viento extremas.
- El ajuste de la GPD se realiza por separado para cada modelo.
Para validar el conjunto de eventos de PRIMAVERA, también se realizaron huellas a partir de las ráfagas de viento del Reanálisis de 5ª Generación del ECMWF (ERA5; Servicio de Cambio Climático de Copérnico, 2017). Este conjunto de datos cubre el período 1979-2014, en una cuadrícula de 0,25°0,25° (~18km de espaciado de cuadrícula a 50° N). Se extrajeron las ráfagas máximas horarias de octubre a marzo y se convirtieron en máximas diarias para poder compararlas con los modelos de PRIMAVERA.