
From Ubuntu and Inkscape, to more specific tools related to Big Data and climate, at Predictia we rely on Open Source projects to our day to day. Why? There are several reasons:
- Having control over what the software does and how it executes it is key in our projects, that usually involve dealing with several TBs of climate data or vast and complex databases with health data.
- Relying on open source adds a layer of accountability and transparency towards our clients, that can then independently inspect the solution we developed.
- Most importantly, we are proud to be part of multiple communities around different open source projects. And just as we benefit from the work of the community, we also contribute to those projects, helping them expand little by little.
Today, we bring you three open source tools for climate data, and a couple of contributions we made to some of them.
A new functionality for a validation tool
Within a Copernicus project that has to deal with evaluation and quality control for the Climate Data Store, we were looking for tools that would enable for quality control of regional datasets. We came across ESMValTool, an Open Source tool to evaluate Earth system models in CMIP. It has a robust set of features that evaluate models against observations, against other models, or compare different versions of the same model.
In principle, it was a no-brainer. The tool fitted perfectly our needs for a robust way of evaluating climate datasets. However, there was a little drawback: ESMValTool wasn't able to process regional datasets. So, we opened a pull request and started working on some aspects:
- Boundary conditions: since the model is a regional one, it has to fit within the bigger picture of global models. Thus, before processing, these datasets need a little bit of adjustment, by taking into account the conditions at the borders of the region.
- Regridding: when dealing with datasets with different resolutions, and comparing models to datasets like ERA5, the data must be interpolated from one grid resolution to a different grid resolution.
For the moment we have tested it with CORDEX datasets, but in principle, adapting the code a little, any regional dataset could be evaluated using this new functionality!
Debugging the intermediate steps
One of our projects plays around with the radar data provided by AEMET, the Spanish State Meteorological Agency, to offer a nowcasting service (stay tuned to our Twitter for updates on that!). But, in order to provide robust predictions, it is critical to have consistent datasets that have timely data, without gaps. Sadly, reality isn’t always that beautiful, and the radar stations sometimes fail to provide the data for a bunch of reasons: it could be that the connection failed and the measurements couldn’t be uploaded, the sensors malfunctioned, or the station was down for maintenance. Whatever the reason is, you end up managing a dataset that has some gaps (albeit not many) in it.
At that point is where we turn to pySTEPS: a modular, free and open-source python framework for short-term ensemble prediction systems. One of the modules enables us to fill in the gaps in our dataset, using an advection correction algorithm. However, when analysing the results in our particular case, something was out of order. So we talked with the developers, opened an issue, and it was quickly resolved.
Visualising climate data
Last but not least, we want to highlight a project that started back in 2009 and is still maintained and growing: ADAGUC. It is our go-to map server, to visualize data over the web, especially when we are dealing with climate data.
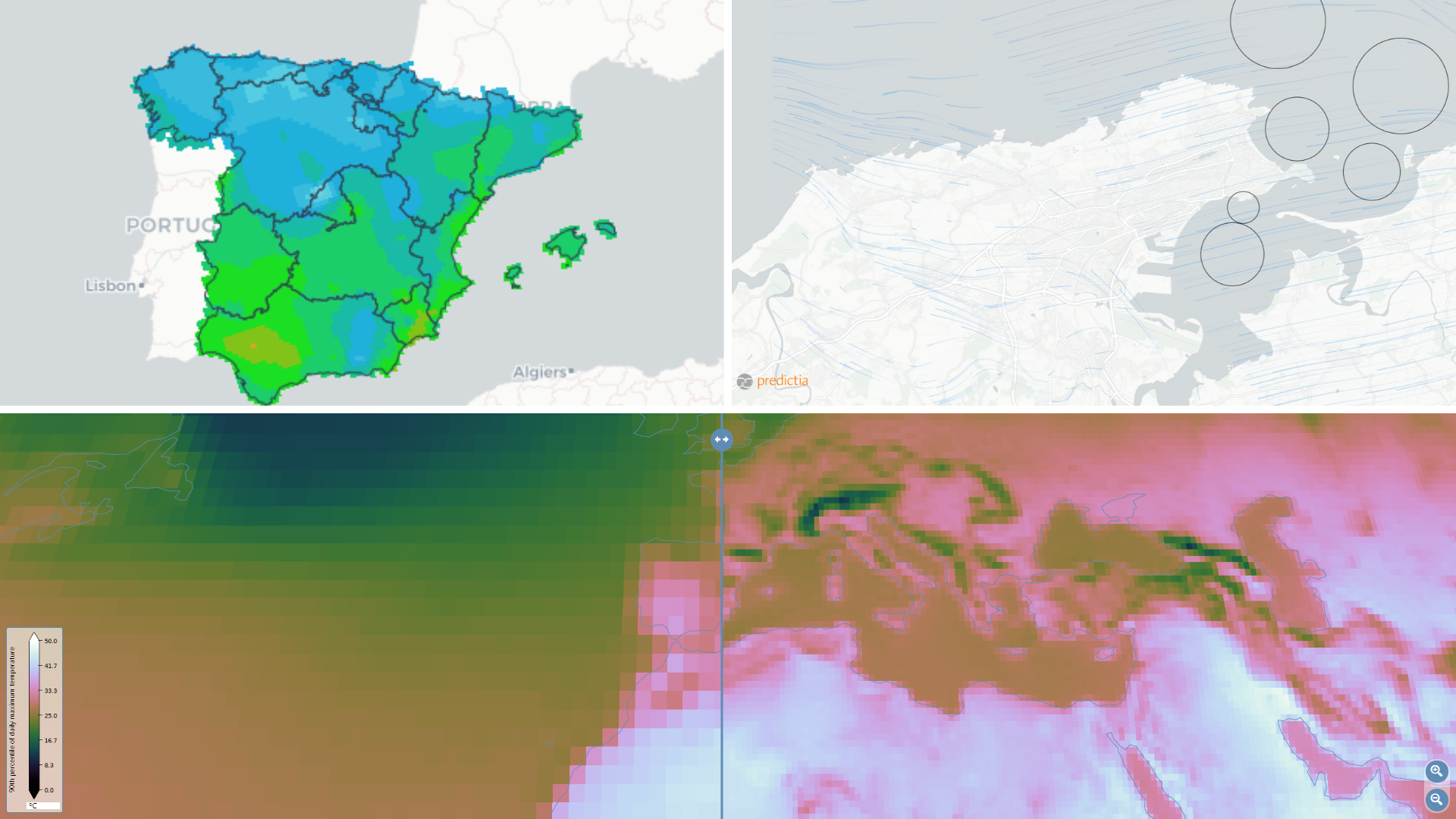
We have used this tool within several projects: the data viewer for the Spanish, the European project Primavera, with Madrid’s Metro… it enables us to visualise climate data ina comprehensible and attractive way that is useful for the users of our tools. And it has an amazing community of developers and users around it that have been maintaining and expandig the project for more than 10 years.