
Todo nuestro sustento proviene de los dos metros más superficiales de la corteza terrestre. La agricultura es una parte fundamental de nuestra sociedad… y también de la transición ecológica. Según la Agencia Medioambiental Europea, la actividad agricultora supone el 10% de las emisiones actuales de gases de efecto invernadero en la UE. Y se prevé que la demanda de comida aumente un 70% en las próximas décadas. Por ello, supone un sector muy relevante en Green Deal europeo. En el centro de las políticas agrarias de la Comisión Europea se encuentra la CAP: la Política Agraria Común. En 2021, la CAP supuso un 33% del presupuesto total de la Unión Europea. Gran parte del presupuesto de la CAP se dedica a ayudas directas para los agricultores:
- funcionan como una red de seguridad y hacen que la agricultura sea más rentable;
- garantizan la seguridad alimentaria en Europa;
- les ayudan a producir alimentos seguros, saludables y asequibles;
- recompensan a los agricultores por aportar bienes públicos que normalmente no pagan los mercados, como la protección del paisaje y del medio ambiente.
Para facilitar la obtención y la evaluación de estas ayudas, las imágenes por satélite de Copernicus proporcionan información muy valiosa. En particular, pueden permitir a la Comisión Europea conocer la superficie total que se ha cultivado en determinadas áreas. Hace un tiempo os contamos un modelo de Deep Learning que nos permitía identificar hábitats naturales usando imágenes del satélite Sentinel-2 de Copernicus. Hoy queremos hablar de un enfoque similar, pero orientado a la agricultura.
¿Cultivo o no cultivo? Esa es la cuestión
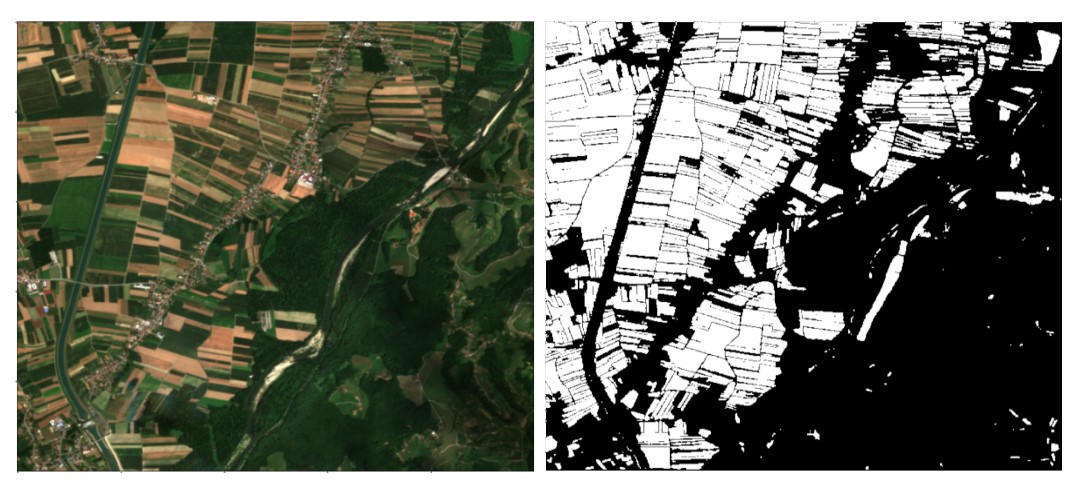
La herramienta la hemos desarrollado dentro de uno de los retos planteados por AI4EO. El objetivo del reto era desarrollar un método que permitiese mapear suelo cultivado, empleando imágenes por satélite de Sentinel, extrayendo la mayor cantidad de información posible de la imagen con resoluciones nativas de 10 metros. En nuestro caso, hemos desarrollado un modelo de Deep Learning que diferencia las parcelas de cultivo en las imágenes por satélite y cuadruplica la resolución original, pasando de los 10 metros originales a una resolución de 2.5 metros.
Localizaciones
En el reto, AI4EO identificaba 100 regiones de interés, situadas en la República de Eslovenia y países vecinos. Cada una de estas regiones mide 5x5 Km, y contiene un montón de información:
- 12 bandas multiespectrales: desde el visible hasta el infrarrojo de onda corta, con una resolución de 10 m.
- Una máscara de información para saber si hay nubes en la imagen. Esto nos permite descartar imágenes que tienen demasiada nubosidad y por tanto hacen imposible discernir qué hay en el suelo.
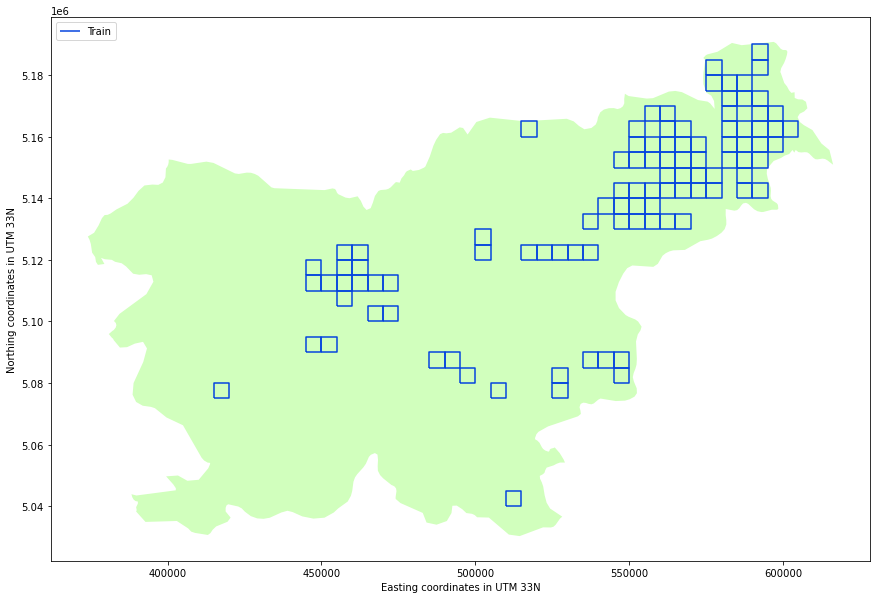
De estas 100 regiones, nosotros las separamos aleatoriamente en 3 tipos:
- Train: regiones que empleamos para entrenar los modelos.
- Validacion: reservamos estas regiones para decidir la mejor configuración de la red.
- Test: estas regiones las empleamos para evitar sobreajustar los modelos y controlar la capacidad de generalización de los modelos.
Esta separación es necesaria, de cara a entrenar los modelos.
Cómo limpiar los datos
Antes de entrenar los modelos, es importante enfocar el problema de una forma constructiva. En nuestro caso, teníamos dos dificultades principales: descartar los datos “no útiles” a la hora de entrenar el modelos, e identificar las parcelas pequeñas de cultivo.
Para entrenar los modelos con datos útiles, recurrimos a la máscara de nubes, que hemos mencionado anteriormente. Esto nos permite descartar imágenes en las que falta demasiada información (porque las nubes cubren gran parte de la imagen).
Además de estos filtros espaciales, para seleccionar las imágenes donde tenemos más información, incluimos un filtro adicional, esta vez de carácter temporal. El conjunto de datos proporcionado por AI4EO abarcaba del 1 de marzo al 1 de septiembre de 2019. En estos 6 meses, la variabilidad del campo es muy alta: hay campos que pasan de estar cultivados a estar cosechados, campos que entran en barbecho… Nuestro modelo por tanto tiene que ser capaz de extraer relaciones a lo largo del tiempo. Para tener en cuenta esta variabilidad, escogimos solo aquellas fechas en las que teníamos imágenes válidas para las 100 localizaciones. Esto nos dejó con sólo 10 días de datos: 10 fechas en las que tenemos un máximo del 20% de cobertura nubosa en todas las localizaciones.

Si miramos las imágenes y empezamos a delinear parcelas cultivadas, las parcelas grandes nos cuesta poco identificarlas… y nuestros ojos empiezan a sufrir al intentar identificar las más pequeñas. Lo mismo les sucede a los modelos de Deep Learning. Para facilitar que estos modelos aprendan a distinguir las parcelas pequeñas, hicimos que en la región de entrenamiento, no todas las parcelas tuvieran el mismo valor (o peso). Las parcelas sin cultivar tienen un peso 1 para el modelo. Las parcelas cultivadas tienen un peso entre 1 y 2, que sigue una distribución normal sesgada que depende del tamaño de la parcela, como en la imagen:
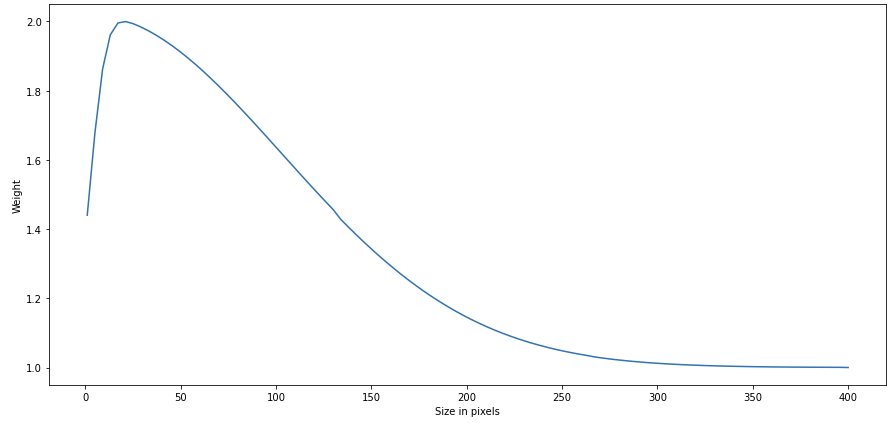
De esta manera, el modelo prioriza las parcelas cultivadas más pequeñas, puesto que si la parcela está formada por 5 píxeles tendrá el doble de peso que si está formada por 400.
Autoencoder y TFCN: comparando dos modelos distintos de Deep Learning
Una vez enfocado el problema, decidimos entrenar dos modelos distintos, para ver sus rendimientos: un modelo autoencoder y un modelo TFCN (Temporal-Frequential Convolutional Network, por sus siglas en inglés)
Modelo autoencoder
Este modelo no emplea los datos preprocesados tal cual, sino una serie de índices de vegetación, que permiten estimar la cantidad, calidad y desarrollo de la vegetación. En vez de escoger un sólo índice, entrenamos modelos para tres índices distintos (NDVI, EVI y RVI) y diversas combinaciones. Además, el aumento de resolución de las imágenes se realiza antes de que el modelo ingente los datos, mediante interpolación lineal.
Finalmente, lo que aprendimos fue que el NDVI es el índice más útil para caracterizar el cultivo, y el modelo no mejoraba al considerar otros índices.
TFCN
En este caso los datos de entrada del modelo son directamente los datos procesados incluyendo la dimensión temporal y se realizan una serie de convoluciones 3D. En este caso, el aumento de resolución lo aprende el modelo (a diferencia del autoencoder, en el que aumentamos la resolución de los datos antes de dárselos al modelo).
Cómo interpretar los resultados del modelo
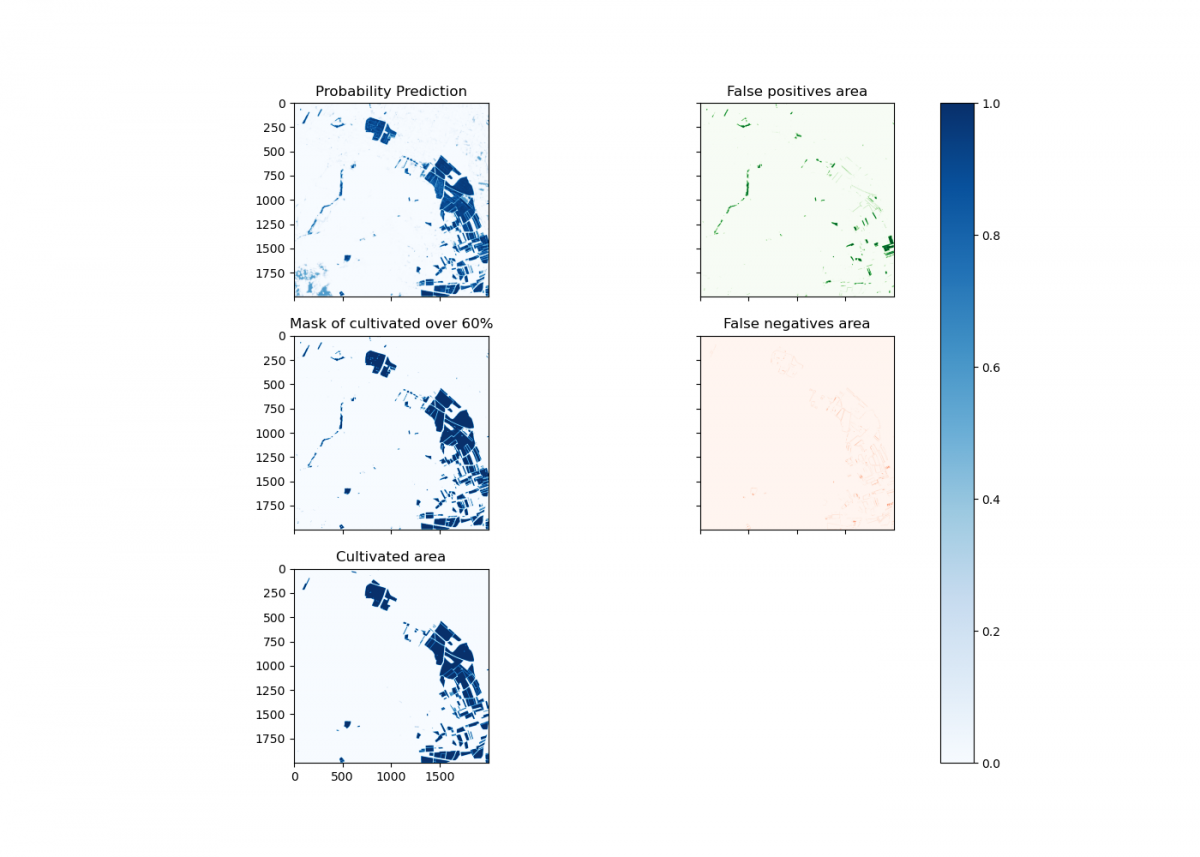
Los dos modelos entrenados (Autoencoder y TFCN) son probabilísticos: en vez de decir si una parcela es campo o no, la predicción da un valor entre 0 (no cultivo) y 1 (cultivo). Por tanto, tenemos que encontrar un umbral a partir del cuál decidir si la parcela es campo cultivado o no. La opción simple hubiera sido recurrir al 50% como umbral. Sin embargo, decidimos refinar un poco más este enfoque. Por ello, recurrimos a la función de error: MCC (Matthews Correlation Coefficient). Se trata de una métrica para evaluar la calidad de clasificaciones binarias. El criterio a seguir era que el umbral seleccionado maximice la puntuación del MCC. De esta forma, el umbral elegido es el óptimo para mejorar la clasificación binaria de cultivo/no cultivo.
Una vez hecho esto, aún había espacio de mejora. Ciertas áreas de agua daban sistemáticamente falsos positivos: indicaban que había cultivo, cuando en realidad eran áreas de agua. Por ello, aplicamos una máscara de agua adicional, calculada con el cociente de las bandas B2 y B11, basándonos en este trabajo. Este enfoque nos permitió alcanzar un 0.771 en la función MCC: quedamos séptimos en el ránking del reto. Por comparación, el equipo ganador consiguió un MCC de 0.862. De cara a mejorar estos resultados, podríamos ampliar y refinar el conjunto de datos de entrenamiento.
Aunque este modelo se aplica a agricultura, el enfoque puede aportar mejoras útiles para muchos otros campos. La transición ecológica trae consigo un montón de preguntas y muchas de ellas tienen que ver con el espacio. ¿Cómo organizamos y empleamos los espacios que nos rodean? ¿Cuánto espacio de la ciudad dedicamos a zonas verdes? ¿Y al transporte colectivo? ¿Qué uso hacemos del campo? ¿Qué consecuencias tiene? Por ello, hay colectivos que hablan de una segunda conquista del espacio. En nuestro caso, estamos orgullosos de poder contribuir a esta segunda conquista del espacio usando herramientas de la primera carrera espacial: los satélites.