Extreme weather events leave tremendous impacts on society. Just in 2021 the impact of extreme weather were enormous throughout the globe, as detailed by the World Meteorological Organization in its 2021 State of the Climate. High temperatures brought rain - rather than snow - to Greenland's ice for the first time. Canadian glaciers underwent rapid melting. Canada and nearby areas of the USA experienced a heatwave that reached nearly 50°C. California's Death Valley recorded 54.4°C as a heatwave peak and many parts of the Mediterranean had record temperatures. In China, the amount of rain that usually falls over several months fell in just a few hours, and parts of Europe were flooded, causing dozens of deaths and millions in damage. In South America, reduced river flows impacted agriculture, transport and energy production in many countries.
That is why researching these extreme events is vitally important. It allows us to understand them better, predict them more accurately and be more prepared. Ultimately, to have more control over their impact. One of the research initiatives we are part of focuses in extreme weather events. It’s Climate Advanced Forecasting of sub-seasonal Extremes or, in short, CAFE. An ITN network that brings together researchers, industry and experts in climatology, meteorology, statistics and non-linear physics. The aim is to train a variety of PhD graduates, whose theses are related to extreme weather. In total, 20 institutions come together, led by the Centre de Recerca Matemàtica. Within this network, Predictia acts as a "host home" for a period of time for some of the network's doctoral students, to complement their training and enable them to carry out specific projects.
Today we interview one of these PhD students, Riccardo Silini, who is about to defend his thesis. His research revolves around two topics: the first is a very specific climate phenomenon, known as the Madden-Julian oscillation (more details below), and a statistical method to analyse causality between different phenomena. Who better to talk about this than Riccardo himself.
Before we get into the nitty-gritty, tell us a bit about yourself.
I come from Switzerland, I got my BSc and MSc in physics at EPFL where I mostly focused on complex networks, theoretical neurosciences and artificial intelligence. Currently I’m doing my Ph.D. in the ITN CAFE project at UPC in Barcelona, which revolves around the forecast of sub-seasonal climate extremes.
Part of your research revolves around the Madden Julian Oscillation. How would you explain this phenomenon to someone who comes across this term for the first time?
It is an atmospheric phenomenon that affects a very specific area of the world: from West Africa to the Pacific Ocean. It is a pattern in the atmosphere whose direct effect is to leave anomalous precipitation. Its main characteristic is that it has two zones: one with more precipitation than usual and one with less.
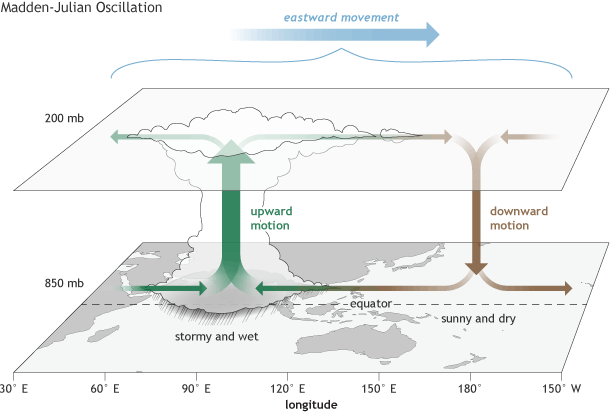
In addition to the actual rainfall generated by the oscillation, why is it important to predict its behaviour?
In addition to leaving more or less rainfall, it influences the summer monsoons in West Africa and India. And going further, it has a bidirectional connection with El Niño (El Niño is influenced by the MJO and vice versa).
What makes this Madden Julian oscillation harder to predict is that sometimes it is active, and sometimes inactive, as if it has a switch. To tell us whether the MJO is active or not, we look at an index, called the RMM, which is used to tell us whether this phenomenon is “on” or “off”. My thesis consists of improving the predictions we currently have about this index, using a Machine Learning approach.
Could you tell us a bit more detail?
For those people who want to get into the technical details, there is a paper we have published in npj Climate and Atmospheric Science. In this paper we apply two approaches to prediction. The first approach is pure Machine Learning: I use a specific type of neural networks, trying to keep the neural networks as simple as possible. As expected, the performance of these networks does not outperform that of climate models. This is normal, because climate models have all the physics of the atmosphere behind them, and therefore simulate reality. However, this Machine Learning approach does outperform other, simpler methods. Moreover, compared to climate models, which are computationally very heavy, the Machine Learning approach is much lighter.
This first approach fits very well with one of the eternal discussions we see in the field of Artificial Intelligence: the friendly rivalry between people who think it is better to use numerical models and those who think it is better to apply Machine Learning, Deep Learning or other techniques. Where would you fall on this spectrum?
Like everything else, it depends on the specific application. In my case, for climate and weather simulations... I think it is better to go down the middle road and let each technique contribute its best part. Let me explain: numerical models simulate the physics behind atmospheric phenomena very well, and give us very valuable information. Therefore, it makes sense to use these models as a first approximation, rather than spending time and resources on a neural network "learning from scratch" these phenomena. It makes no sense to put this learning burden on the network when we already know the physics.
This is precisely the second approach we explore in the paper. We take a numerical model as a starting point, and try to improve its predictions, post-processing with Machine Learning. In particular, we use the best numerical model currently available, developed by the ECMWF, which has the best prediction skill for the Madden-Julian oscillation. We then take a feed-forward neural network and train it to correct the model results. The result is a post-processing that improves the prediction of the numerical model and is also better than more classical types of post-processing, such as multiple linear regression.
We have also seen that it improves a very specific aspect of the prediction: when the Madden Julian oscillation is about to enter the maritime continent, the physics becomes more complex, and the predictive ability of the numerical models drops. It is just at this point that the correction with Machine Learning has the greatest effect, because it manages to correct this skill drop quite well.
In short, I think the most useful thing to do is to devote resources to improving both: improving the numerical models as we discover new aspects of the physics behind them; and improving the post-processing of Machine Learning, which bridges that last gap between models and reality, to make more accurate predictions.
Let's change the subject and talk about another focus of your research: causality. Can you explain a bit about where your interest comes from?
In our everyday life, we usually have no problem seeing causality directly. If we kick a ball, it shoots out. However, when we move into more abstract or complex areas... causality becomes a bit harder to see.
The perfect example is atmospheric weather: these are complex systems, with a multitude of individual parts that interact with each other and have effects that we could not know by studying each part separately. Its a tangled web of elements causing effect in each other.

However, you can use the idea of causality in any field, not just weather.
Exactly. In my case, we start with many time series that tell us how various parameters evolve separately. With that amount of information, it is difficult to see the relationships between one thing and another.
In statistics, one of the methods we use to look at this causality is Granger causality. Rather than telling us whether X causes Y, it tells us whether X predicts Y. Granger causality gives us a metric, an indicator, of how good a parameter is at predicting the behaviour of another parameter.
And what you are researching is a method to improve these metrics.
Yes, we have developed a tool that allows us to analyse causality, understood in the Granger sense I mentioned earlier: rather than saying X causes Y, it allows us to say that X predicts Y. The theoretical details are in this paper in scientific reports and the code to implement the system is available on my GitHub.
How would you recommend using this tool?
The first thing is that it works with short time series, 500 points. This is because at that size, the library is much faster than the Granger causality library that already exists in Python.
Second, it is a quick diagnostic tool. Instead of analysing all the options in depth, it allows us to make a quick study of the information we have to see possible causal relationships. The idea behind the library is that the user gives as input a matrix with the time series to be analysed and you get as output a causality matrix.
Lo segundo, es que se trata de una herramienta de diagnóstico rápido. En vez de analizar todas las opciones a fondo, nos permite hacer un estudio rápido de la información que tenemos para ver posibles relaciones de causalidad. La idea detrás de la librería es que el usuario dé como input una matriz con las series temporales a analizar y que obtengas como resultado una matriz de causalidad.
Second, it is a quick diagnostic tool. Instead of analysing all the options in depth, it allows us to make a quick study of the information we have to see possible causal relationships. The idea behind the library is that the user gives as input a matrix with the time series to be analysed and you get as output a causality matrix.
And now that you're going to be at Predictia for a while, what are you tinkering with?
At the moment we can't tell you much detail, but it has to do with fire risk indexes and causality.
To find out more, we'll have to wait for Riccardo to finish his stay with us - stay tuned!