
En un contexto de creciente concienciación y preocupación a nivel mundial por la calidad del aire, varios gobiernos están poniendo en marcha políticas verdes para reducir los niveles de contaminación en las zonas urbanas. La ciudad de Madrid, una de las capitales europeas más pobladas, tiene una extensa red de carreteras y 4,2 millones de vehículos registrados, lo que se traduce en problemas de congestión y mala calidad del aire, y afecta de manera directa a la salud humana.
En los últimos años, dos acontecimientos han reducido de forma significativa el tráfico en la ciudad de Madrid: la implantación de Madrid Central (un perímetro de bajas emisiones) y las restricciones de tráfico debido a la pandemia de la COVID-19. Aprovechando este marco experimental, se realizaron una serie de simulaciones a través de técnicas de aprendizaje automático para comprobar la influencia de las condiciones meteorológicas respecto a la reducción de la contaminación provocada por el tráfico.
El objetivo de este estudio es cuantificar la influencia del tráfico y la meteorología en la calidad del aire en la ciudad de Madrid (Fig. 1), aprovechando el marco experimental proporcionado por los dos citados eventos, con el objetivo de intentar demostrar la tesis por la cual para evaluar la eficiencia de medidas que impliquen una reducción del tráfico hay que tener en cuenta que la parte meteorológica juega un papel fundamental.
Metodología
Para este trabajo, se requirieron datos de calidad del aire, tráfico y meteorológicos proporcionados por el Ayuntamiento de Madrid y la empresa Predictia Intelligent Data Solutions. Una vez se procesaron los datos, estos se sometieron a un análisis exploratorio para determinar la presencia de valores atípicos y si estos se deben a episodios altos de contaminación.
Se crearon cuatro conjuntos de datos que incluyen información sobre tráfico, contaminación y meteorología en las siguientes zonas de Madrid:
- Zona 1: Retiro.
- Zona 2: M-30.
- Zona 3: Casa de Campo.
- Zona 4: Plaza del Carmen (Madrid Central).
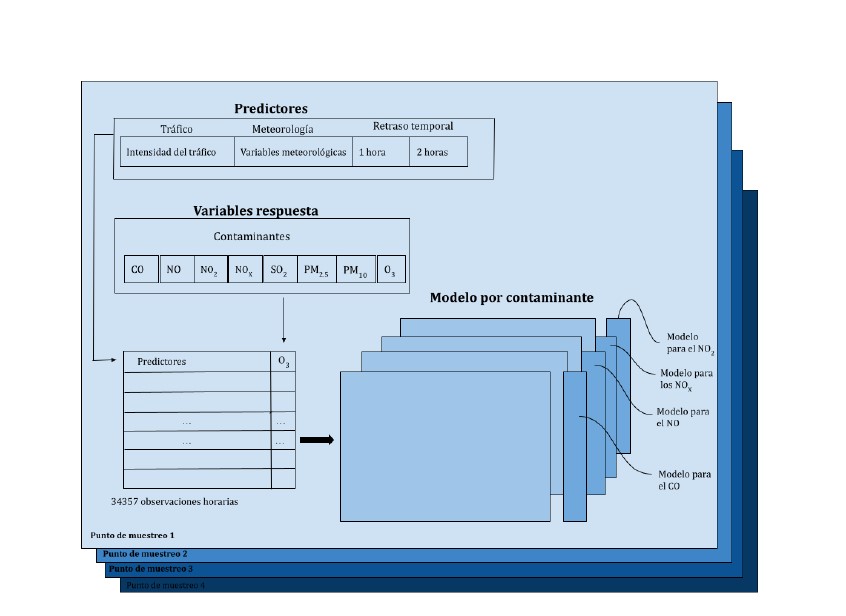
Para estudiar la relación entre los distintos contaminantes, el tráfico y las variables meteorológicas, se consideró un aspecto clave: la persistencia de estos factores en la atmósfera. Por esta razón, se aplicaron dos retrasos temporales, de una y dos horas a todos los predictores (tráfico y meteorología) en cada uno de los conjuntos de datos. La Figura 2 ilustra la estructura de cada conjunto de datos.
En todos los puntos de muestreo se observó que los óxidos de nitrógeno (NOx = NO + NO2) tienen una correlación de alrededor de 0,5 con el tráfico, mientras que el monóxido de carbono (CO) muestra una correlación de 0,3.
Por otro lado, el ozono (O3) está fuertemente correlacionado con las variables meteorológicas relativas a la radiación solar. El material particulado (PM) también se relaciona con el tráfico, aunque está más vinculado a la industria y el uso de calefacciones. A raíz de este primer análisis, el estudio se centró en el monóxido de carbono y los óxidos de nitrógeno.
El segundo análisis se centró en evaluar la importancia de los diferentes predictores (meteorología y tráfico) en relación con el nivel de contaminante a través de técnicas de aprendizaje automático, particularmente utilizando modelos de Random Forest. El Random Forest es un algoritmo basado en la construcción de múltiples árboles de decisión para mejorar la precisión y evitar el sobreajuste, mediante la combinación de los resultados de cada árbol para hacer una predicción final. Este análisis nos proporcionó una estimación inicial de cuáles son las características más relevantes para construir un modelo predictivo y cuáles tienen una influencia limitada, lo que permite eliminarlas en etapas posteriores del modelado, optimizando así el tiempo de cómputo.
Una vez establecidas las variables objetivo y los predictores se generaron dos modelos para cada contaminante en cada punto de muestreo (Fig. 2). El primero utilizó como datos de entrenamiento los años 2017, 2018 y 2019, dejando el año del inicio de la pandemia (2020) para prueba. El segundo modelo usó los años 2017, 2018 y 2020 como entrenamiento, dejando el año en que se puso en marcha Madrid Central (2019) para prueba.
Para seleccionar la mejor estrategia de modelado para las simulaciones finales, se evaluaron varias técnicas de minería de datos, incluyendo GLM, k-NN y Random Forest. GML es un algoritmo avanzado de regresión lineal, mientras que k-NN se basa en la cercanía de los datos a sus vecinos más próximos. La técnica basada en árboles de decisión, Random Forest, demostró ser la más efectiva, superando a las demás en tres métricas clave: coeficiente de determinación (R²), raíz del error cuadrático medio (RMSE) y ratio de varianzas.
Simulaciones
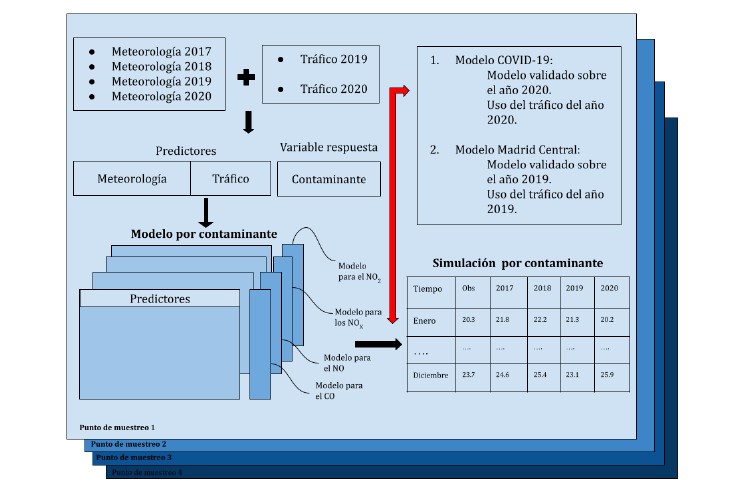
Una vez identificados los mejores modelos para cada contaminante en los distintos puntos de muestreo mediante técnicas de aprendizaje automático, se realizaron simulaciones para cuantificar la influencia de las condiciones meteorológicas y el tráfico en la calidad del aire. Se hicieron dos tipos de simulaciones: una para el periodo de Madrid Central (2019) y otra para el periodo COVID-19 (2020), usando los modelos validados para esos años. Estas simulaciones se centraron en la Gran Vía, única zona que abarca ambos períodos de reducción de tráfico.
Primero, se generó un conjunto de datos combinando los datos meteorológicos de un año con los de tráfico de 2019 o 2020. Luego, se aplicó el modelo correspondiente según el tráfico utilizado:
- Modelo COVID-19 (validado con datos de 2020).
- Modelo Madrid Central (validado con datos de 2019).
Este proceso se repitió para cada año (2017-2020), generando cuatro simulaciones, cada una con los datos meteorológicos de un año específico y los datos de tráfico de uno de los dos eventos estudiados (Fig. 3). Esto permitió estimar cómo influyen las condiciones meteorológicas, además del tráfico, en la calidad del aire.
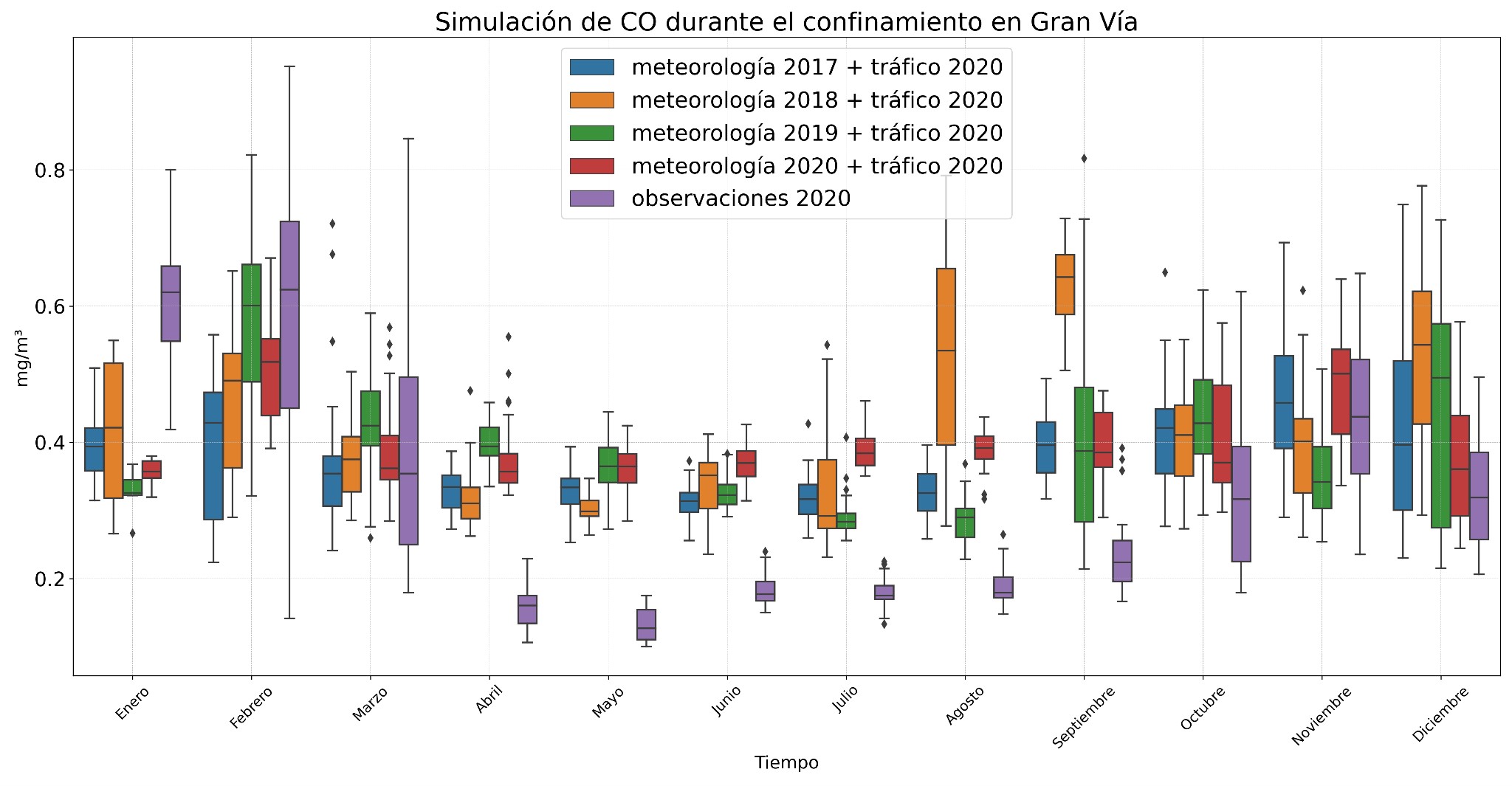
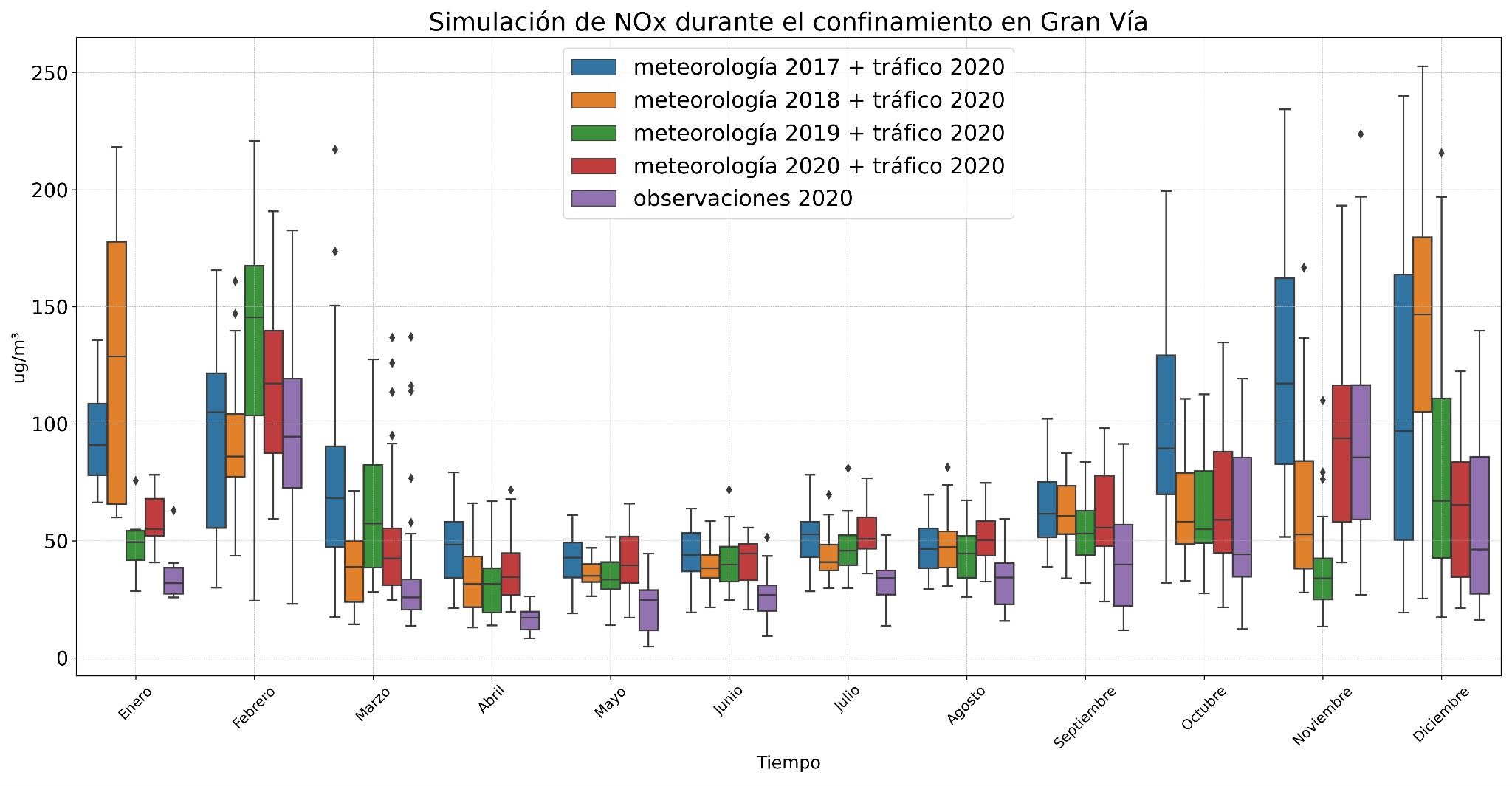
Las figuras 4 y 5 muestran las simulaciones para los contaminantes CO y NOx generadas con el modelo validado para 2020. Se observaron algunos valores anómalos para el CO debido a las obras en Gran Vía, lo que hizo que las predicciones no se ajustaran tan bien a los datos reales de 2020. Sin embargo, las simulaciones para CO usando otras condiciones meteorológicas mostraron valores más altos, especialmente en 2018, con un pico en agosto y septiembre. Por otro lado, las simulaciones con los datos meteorológicos de 2017 y 2018 muestran una disminución de su concentración en febrero y marzo, posiblemente debido a eventos de borrasca que limpian la atmósfera.
Los modelos para los NOx captaron mejor la variabilidad de los datos, mostrando un aumento en los niveles durante los meses de invierno (diciembre y enero) cuando cambiaron las condiciones meteorológicas, lo cual podría deberse a la inversión térmica, que dificulta la dispersión de contaminantes. En verano, las concentraciones apenas variaron.
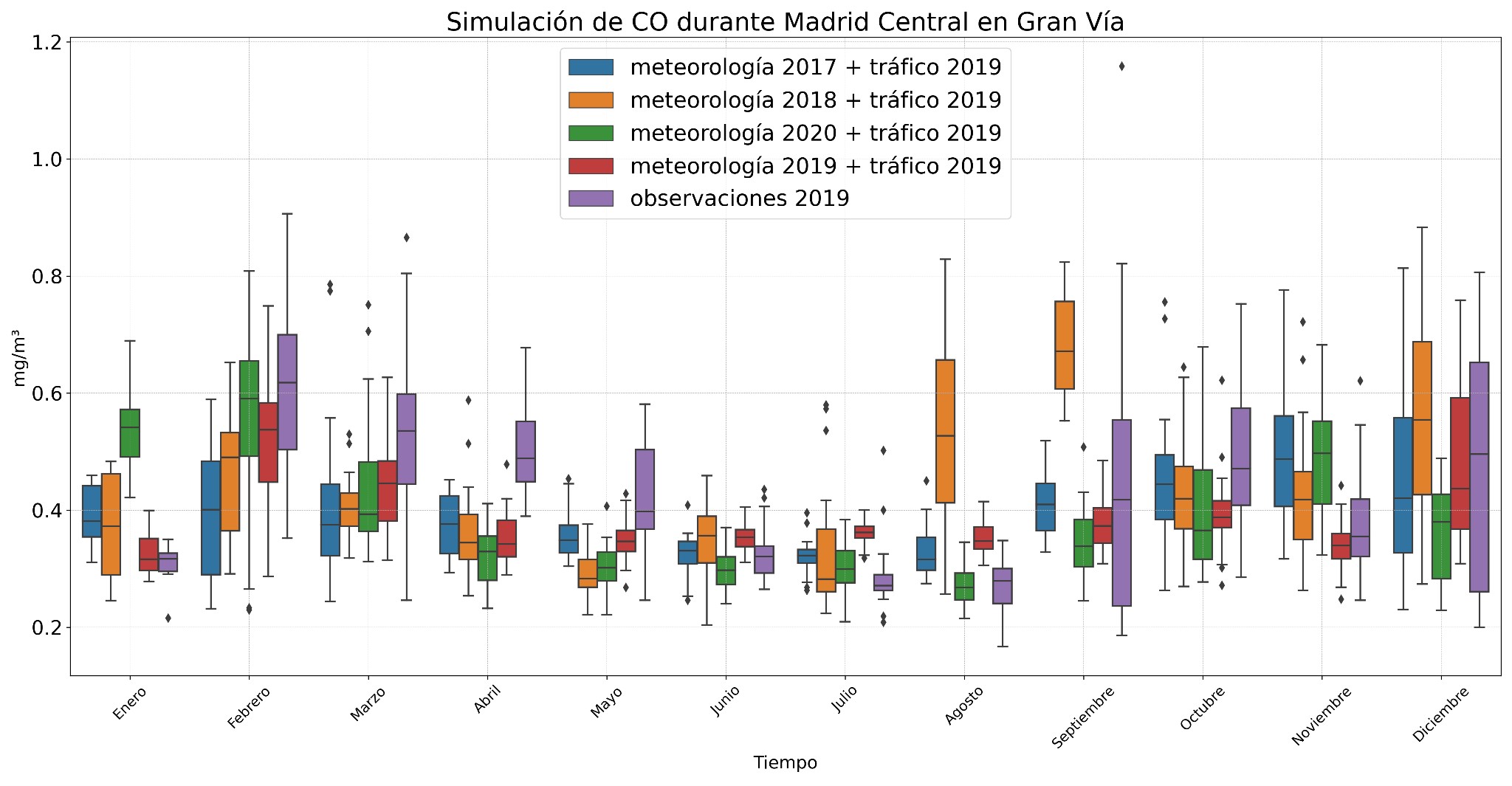
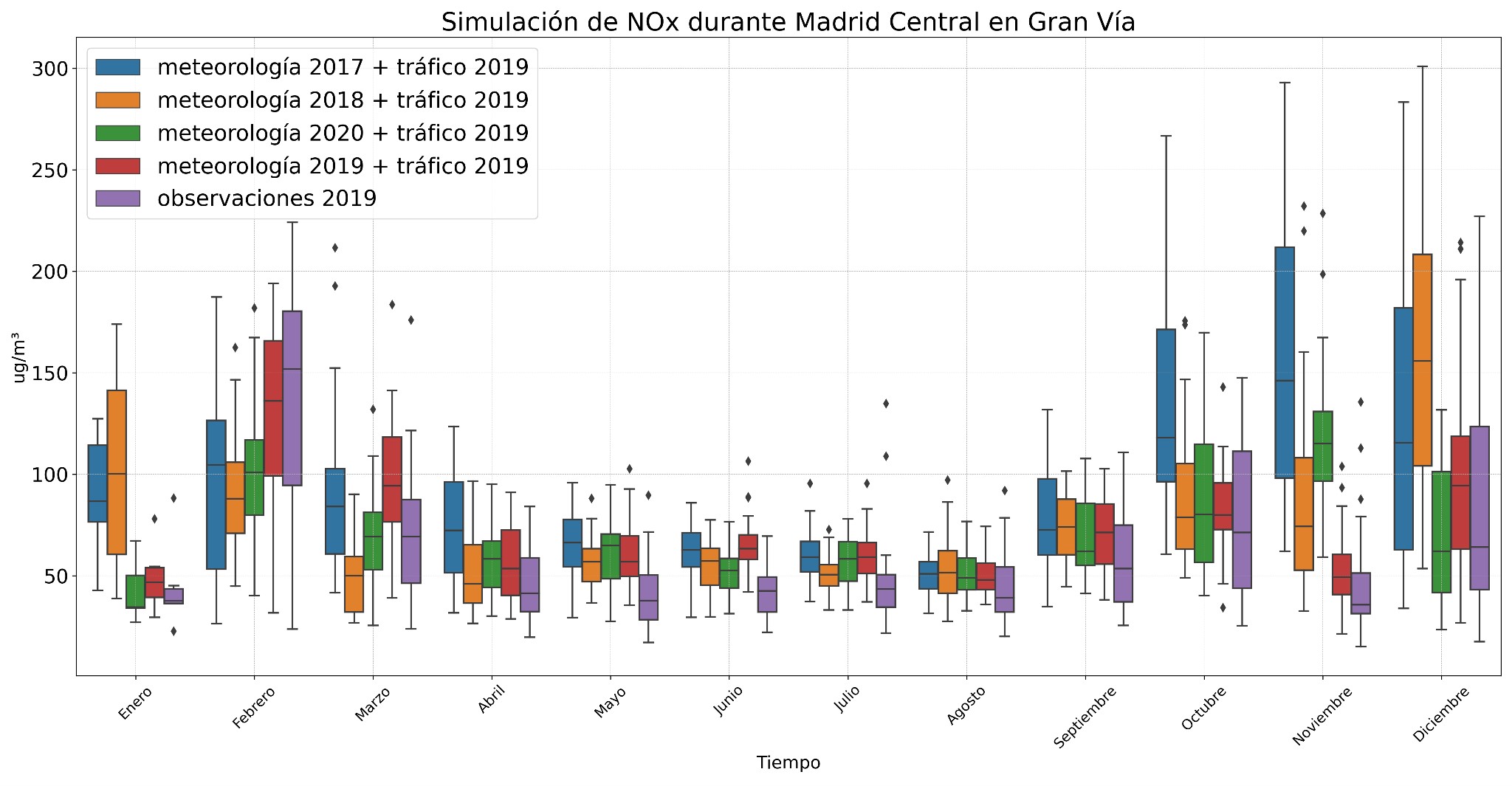
El segundo experimento aplicó el modelo validado para 2019 (Madrid Central) a nuevos conjuntos de datos, combinando el tráfico de 2019 con diferentes condiciones meteorológicas. Al comparar las simulaciones generadas con este modelo y las obtenidas con el modelo de 2020, se observó que las simulaciones del modelo de 2019 mostraron menos variabilidad. Esto se debe a que la reducción del tráfico en 2019 no fue tan drástica como en 2020, cuando hubo restricciones por la COVID-19.
En la figura 6, se aprecia que el modelo de 2019 explica mejor la variabilidad del CO, mostrando un pico de concentración en agosto y septiembre al combinar el tráfico de 2019 con la meteorología de 2018, similar al comportamiento observado con el modelo de 2020.
Para los NOx (Fig. 7), las simulaciones con el modelo de 2019 también captan mejor la variabilidad de los datos. Cuando se combinan con diferentes datos meteorológicos, se observa un aumento en las concentraciones de estos compuestos durante los meses de invierno, particularmente en diciembre y enero, como se muestra en las gráficas anteriores. En verano, las concentraciones de compuestos nitrogenados apenas varían al cambiar las condiciones meteorológicas.
Conclusiones
Estas simulaciones nos permiten concluir que la influencia de las condiciones meteorológicas es más notable en los meses de invierno y otoño, puesto que, al agregar datos meteorológicos de otros años, la concentración de los compuestos nitrogenados aumenta. Ocurre lo mismo con el monóxido de carbono. Sin embargo, en los meses de verano, las concentraciones apenas varían.
Así pues, en base a este primer estudio, podemos concluir que no solo el tráfico determina los niveles de contaminación, sino que la variabilidad debida a las fluctuaciones de las condiciones meteorológicas juegan un papel relevante a la hora de evaluar la eficiencia de una medida de reducción de tráfico. Estas conclusiones están en consonancia con la literatura existente sobre calidad del aire, que destaca la importancia de considerar tanto las fuentes de emisión (e.j., tráfico) como las condiciones meteorológicas para gestión de la contaminación atmosférica.
Este artículo se basa en el Trabajo de Fin de Máster de nuestro compañero Sergio Natal. Si quieres conocer más detalles, puedes acceder a él en este repositorio de la Universidad de Cantabria.