
Hace un mes se presentó la versión final del Atlas Interactivo del IPCC. Ahora que ya ha pasado todo el revuelo, queremos pararnos a hablar sobre los aspectos técnicos de su implementación. Después de todo, tras procesar cientos de TB (con más de 1,5 millones de horas de computación), hemos aprendido algunas lecciones que queremos compartir. Este será un post largo, así que lo hemos dividido en varias secciones, para que puedas visitar directamente aquella que más te interese:
Construir sobre código abierto

Si te paras a mirar el stack de tecnologías de la imagen, podrás ver que gran parte del software es de código abierto. En Predictia, una de nuestras filosofías base es confiar en soluciones abiertas. Por eso, junto con el Grupo de Investigación sobre Clima del IFCA, hemos hecho hincapié en el uso de soluciones abiertas desde el principio del proyecto. Algunas de ellas se encuentran en el núcleo del Atlas Interactivo:
- ADAGUC: un sistema de información geográfica para visualizar archivos netCDF (los empleados para la información climática) vía web. El software consiste en una aplicación C++ de parte del servidor y una aplicación JavaScript del lado del cliente. El software ofrece varias funciones para acceder y visualizar datos a través de la web. Un punto fuerte a su favor es que sigue los estándares del OGC: estos incluyen los Servicios de Cartografía Web (WMS por sus siglas en inglés) para la visualización en línea y los Servicios de Cobertura Web (WCS por sus siglas en inglés) para la descarga de datos raster. En particular, tenemos que agradecer especialmente a KNMI (el organismo que está detrás de ADAGUC), por su ayuda. Han implementado algunas características que fueron solicitadas específicamente por el equipo del Atlas, como la compatibilidad con la proyección Robinson centrada en el Pacífico.
- Metaclip: en el pasado hemos hablado largo y tendido sobre Metaclip, así que no vamos a entrar en detalles. En pocas palabras, Metaclip es un estándar de metadatos para la información climática que permite a los usuarios controlar y rastrear la procedencia de todos los datos mostrados en el Atlas Interactivo, utilizando un enfoque semántico.
- Xarray: se trata de un proyecto de código abierto y un paquete de Python que hace que trabajar con matrices multidimensionales etiquetadas sea sencillo, eficiente y divertido. Xarray introduce etiquetas en forma de dimensiones, coordenadas y atributos sobre matrices crudas tipo NumPy, lo que permite una experiencia de desarrollo más intuitiva, más concisa y menos propensa a errores. El paquete incluye una amplia y creciente biblioteca de funciones agnósticas para el análisis avanzado y la visualización con estas estructuras de datos. Xarray se inspira en Pandas, el popular paquete de análisis de datos centrado en los datos tabulares etiquetados, y lo toma prestado. Está especialmente adaptado para trabajar con archivos netCDF siguiendo las convenciones CF, que fueron el origen del modelo de datos de xarray, y se integra estrechamente con dask para la computación en paralelo.
- Dask: Dask es una biblioteca flexible para la computación paralela en Python. Ha sido extremadamente útil (¡y divertido!) aprovechar al máximo los recursos de HPC proporcionados por el IFCA para procesar grandes conjuntos de datos.
Gracias a estas soluciones que ya existían, no tuvimos que reinventar la rueda: nos bastó con centrarnos en integrar las piezas tecnológicas del puzzle. Así, pudimos dedicar más esfuerzos a otras áreas, como la evaluación de la calidad. Sin embargo, en los tres años de desarrollo del Atlas Interactivo no sólo nos hemos beneficiado del uso de soluciones abiertas, sino que también hemos contribuido a ellas, localizando fallos y ayudando a resolverlos.
Además, todos los scripts utilizados para procesar los datos están disponibles abiertamente, a través del repositorio Github del Atlas Interactivo. Y por último, la razón más importante para confiar en las soluciones abiertas: la transparencia y la imparcialidad. Facilita la revisión no sólo de los datos en sí, sino de cómo se han procesado. Todo esto conecta muy bien con el siguiente capítulo de este post: el proceso de revisión del IPCC.
Proceso de revisión: datos FAIR y su gobernanza
Entre los principales pilares del IPCC están la transparencia y la trazabilidad. Para lograrlo, los diferentes borradores del Informe de Evaluación son revisados exhaustivamente por expertos y gobiernos. El proceso de revisión incluyó una amplia participación, con cientos de revisores y más de 78000 comentarios. En total, el informe se sometió a tres revisiones del IPCC: el borrador de primer orden, el borrador de segundo orden y la versión final. En cada una de estas etapas, se congeló el estado del Atlas Interactivo, para garantizar que todos los revisores tuvieran acceso a la misma información. Para facilitar la revisión, el Atlas Interactivo proporcionaba enlaces permanentes únicos, de modo que los revisores podían enviar enlaces a la información específica que estaban revisando en ese momento.
Dado que el Atlas Interactivo es una herramienta de apoyo al capítulo de Atlas del IPCC, fue sometido al mismo nivel de escrutinio. Uno de los primeros obstáculos que encontramos fue el enorme volumen de datos brutos que maneja el Atlas, del orden de cientos de TB. Esto se debe al elevado número de conjuntos de datos y variables que contiene la herramienta... y a algunas características específicas que añaden complejidad a los datos. Un buen ejemplo de ello es la función de temporada personalizada, que permite ir más allá de los datos de primavera/verano/otoño/invierno y seleccionar el rango de meses en el que centrarse. Esto es relevante, por ejemplo, para estudiar los monzones, que presentan estaciones variables en todo el mundo. Esta función de estaciones por sí sola multiplica por 145 el volumen de datos que maneja el Atlas, debido a las necesidades de los conjuntos de datos que se incluyen.
Para facilitar la revisión del Atlas Interactivo, adoptamos los principios FAIR de encontrabilidad, accesibilidad, interoperabilidad y reutilización. Esto se traduce en varios puntos sobre los propios datos:
- Fuentes: todos los datos incorporados al Atlas Interactivo proceden de fuentes rastreables: las iniciativas CMIP y CORDEX para las proyecciones climáticas; ERA5, E-OBS y otros conjuntos de datos para las observaciones históricas; y la iniciativa PMIP para los registros paleoclimáticos. Para obtener los diferentes conjuntos de datos, el equipo del IFCA utilizó dos fuentes principales: Copernicus Climate Data Store y ESGF.
- Post-procesado reproducible: el post-procesado es acordado por el IPCC. Para encajar en la arquitectura del Atlas Interactivo, el conjunto de datos debe someterse a una serie de post-procesos que unifican el formato, los sistemas de coordenadas y otros aspectos de los datos. Este proceso se ha implementado utilizando herramientas de código abierto y está bien documentado para que sea reproducible.
- Metadatos estándar: todo el post-procesado se describe de principio a fin utilizando matadatos estándar. Esto es posible gracias a Metaclip.
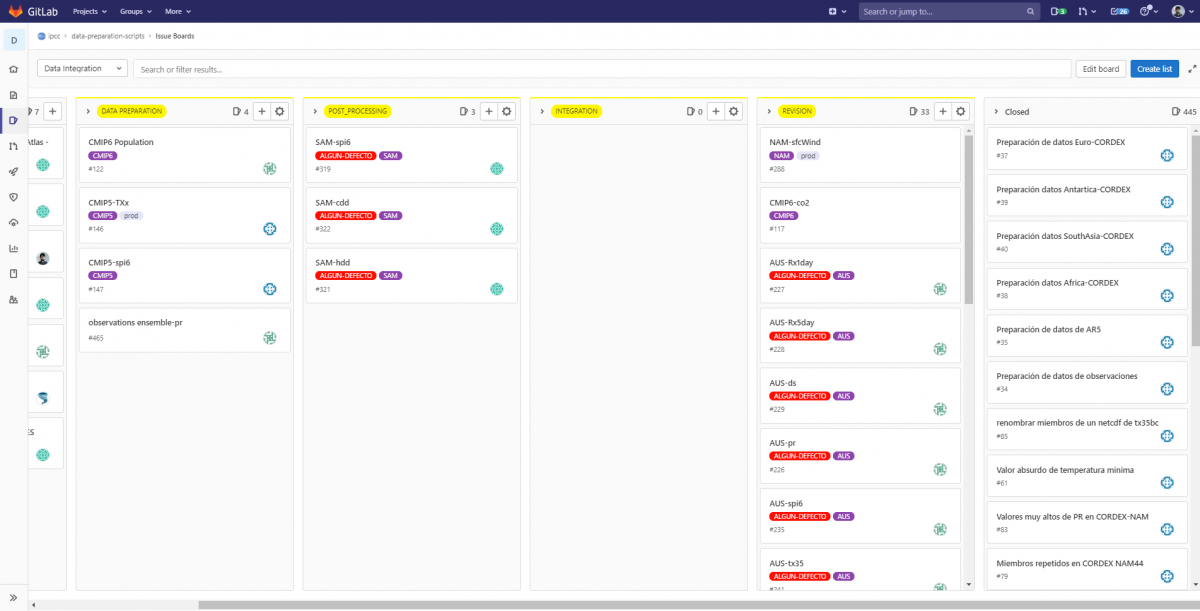
El primer paso en el tratamiento de los datos fue técnico, y lo llevó a cabo el equipo del Atlas:
- Adquisición y preparación de datos: todos los datos brutos proceden de fuentes fiables, como las proyecciones climáticas CMIP5 y CMIP6, así como de modelos regionales como CORDEX. La preparación de los conjuntos de datos va más allá de la descarga de los datos de sus repositorios. En esta fase, se ha hecho un esfuerzo especial para unificar la estructura de los datos y abordar cuestiones técnicas bien conocidas entre la comunidad de modelización climática. Una de esas cuestiones es, por ejemplo, la unificación del calendario: sólo unos pocos Modelos Climáticos Globales utilizan un calendario gregoriano estándar con 365 días por año en los años no bisiestos, y 366 días por año en los años bisiestos. La mayoría de los MCG utilizan el llamado calendario "no bisiesto" (o "de 365 días"), que tiene 365 días en cada año. Y algunos modelos funcionan incluso con calendarios de 360 días, en los que cada año tiene 360 días (12 meses de 30 días cada uno). El equipo del IFCA se ha ocupado de unificar y evaluar todos estos aspectos.
- Posprocesado de datos: una vez descargados y unificados los conjuntos de datos climáticos, llega el momento de posprocesarlos. Esto incluye detalles como la interpolación de los datos para que encajen en una cuadrícula geográfica común, la agregación de los datos en las diferentes regiones utilizadas por el Atlas Interactivo, contemplando también diferentes agregaciones temporales, y el cálculo de algunas métricas. Esto se calculó utilizando las capacidades de HPC proporcionadas por el IFCA, y para manejarlo, nos apoyamos en CDO, Climate4R y Slurm (para gestionar los trabajos en las instalaciones de supercomputación).
- Integración de los datos: en esta fase, los conjuntos de datos se integran en el portal del Atlas Interactivo, y se realizan varias comprobaciones sobre la visualización y la interactividad con las diferentes características de la herramienta: metadatos, franjas climáticas, franjas estacionales, gráfico GWL... Además, algunos conjuntos de datos específicos se comparan con sus equivalentes estáticos que se incluyeron en el capítulo del Atlas del informe AR6, para garantizar su coherencia.
Gracias a este proceso minucioso y sistemático, el equipo de Atlas pudo detectar y subsanar fallos y otros errores en los datos, su tratamiento y la propia plataforma.
Un circo multipista: integraciones en Gitlab
Este proceso de revisión del IPCC nos obligó a multiplicar el número de instancias que habíamos desplegado del Atlas Interactivo. Acabamos teniendo cuatro entornos diferentes: uno interno, para desplegar nuevos datos, funcionalidades y realizar la revisión interna; y tres de ellos para las revisiones del IPCC, los expertos y los gobiernos. Tener tantos entornos diferentes que utilizan un conjunto común de datos fue una gran lección para nosotros en materia de integración continua. Tuvimos que crear una serie de trabajos integrados en nuestro Gitlab, en función de lo que queríamos cargar en cada entorno, y hacerlo de forma automática. Estas idas y venidas de datos a través de diferentes entornos fue una constante durante todo el proyecto. Así que nos obligó a desarrollar diferentes monitores de estado que nos permitieran conocer el estado de las cosas en cada momento, a través de los entornos. De este modo, podíamos responder al tiempo, algo que fue crucial especialmente durante el proceso de revisión por parte de expertos y gobiernos, cuando la herramienta experimentó cientos de visitas simultáneas. Por supuesto, todo esto se quedó pequeño al lado del gran número de visitas que experimentó la herramienta el día del lanzamiento.
Satisfacer las demandas y expectativas de los usuarios: más rápido y robusto
Una vez que la herramienta se hizo pública, tuvo una gran acogida: casi 500.000 en la primera semana, un tiempo medio de respuesta a las consultas de los usuarios de 1,5 segundos, y la carga de recursos en el pico de visitas fue de alrededor del 20% del total. En general, unas métricas muy buenas. ¿Cómo conseguimos esto?
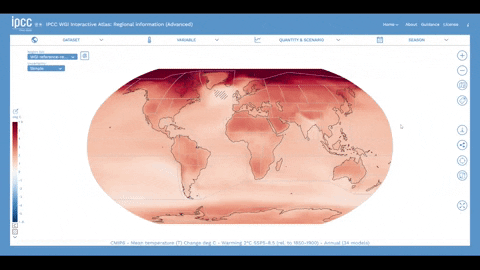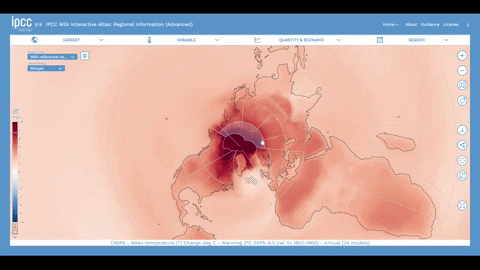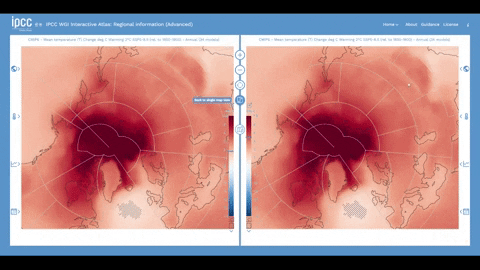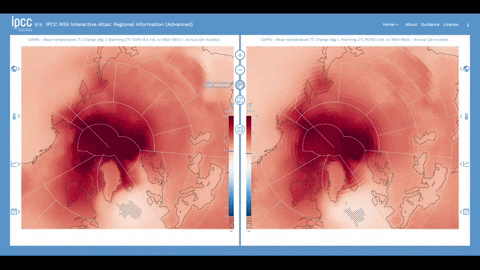
Históricamente, en los sistemas GIS, normalmente el servidor se encargaba de generar una imagen que luego se servía en tu ordenador. Sin embargo, a medida que los ordenadores, móviles y otros dispositivos se han hecho más potentes, se han abierto infinitas posibilidades. Los dispositivos más potentes permiten servir los datos directamente al dispositivo que tienes en tus manos y dejar que éste haga el trabajo gráfico (generar los mapas en lugar de limitarse a cargar una imagen). Este es el caso, por ejemplo, de web-gl y otras librerías gráficas. En el caso de la información climática, este enfoque no puede funcionar: la cantidad de información es tan grande, que el dispositivo tendría que hacer demasiado trabajo... dificultando el rendimiento. Además, en el caso del Atlas Interactivo, el IPCC tiene un alcance global. Y eso significa que el Atlas Interactivo debe funcionar en todo tipo de ordenadores: nuevos y viejos, gigantes de los juegos y ordenadores antiguos con Pentiums III. Este principio de universalidad fue un principio rector durante todo el desarrollo.
Así que optamos por un enfoque mixto:
- En primer lugar, el usuario del Atlas selecciona los datos que desea consultar: conjunto de datos, variable, escenario de cambio climático, etc.
- Esto genera una petición al servidor que se dirige al correspondiente conjunto de datos precalculado.
- A continuación, el servidor genera la imagen correspondiente para mostrarla en el Atlas
Este enfoque también nos permitió implementar características interesantes, como la leyenda de colores personalizable para el usuario: el usuario modifica los valores de la leyenda, lo que genera una petición al servidor con los nuevos parámetros, que luego devuelve la imagen correspondiente.
Sin embargo, este proceso no era tan óptimo y escalable como esperábamos. Imaginemos el pico de visitas en el lanzamiento, cuando obtuvimos 13.000 visitas en una hora. Cada usuario que entró en la herramienta es una petición al servidor, que tendría que generar la imagen y luego enviarla. Está claro que calcular previamente los conjuntos de datos alivia parte del esfuerzo. Sin embargo, a pesar de la eficacia de ADAGUC en la generación de imágenes, este proceso sigue consumiendo recursos. Así que aquí viene la segunda parte de la estrategia: la caché dinámica (para los lectores no técnicos: una caché es una ubicación de almacenamiento reservada que recoge datos temporales para ayudar a que los sitios web, los navegadores y las aplicaciones se carguen más rápido). En nuestro caso, la caché del servidor almacena los mapas que corresponden a los datos más solicitados. Por supuesto, el primero es un hecho: el mapa de aterrizaje que mostramos al entrar en la herramienta. Pero el resto son totalmente impulsados por el usuario. Si un periódico o una publicación en las redes sociales que enlaza con una vista específica del Atlas Interactivo se hace viral, la imagen generada se almacena en la caché y luego se sirve automáticamente a la solicitud. Gracias a esta estrategia incorporada, el Atlas Interactivo no puede morir de popularidad, al evitar generar imágenes idénticas una y otra vez.
En general, estos son los detalles técnicos que sustentan el Atlas Interactivo y que están detrás de la rápida experiencia de usuario que ofrece. Por supuesto, otra parte se encuentra dentro de la UX/UI del Atlas Interactivo... pero este tema merece una entrada de blog propia, ya que esta se ha hecho demasiado larga.