Nuestro modelo de visión por ordenador de última generación, surgido del programa de ECMWF Code 4 Earth, ya está disponible en Hugging Face. Olvídate de las limitaciones de los conjuntos de datos de reanálisis de baja resolución: ConvSwin2SR te permite un acceso rápido y rentable a datos meteorológicos de alta resolución en la región mediterránea que podrían utilizarse para políticas de mitigación y adaptación al cambio climático. A continuación, te mostramos esta nueva herramienta.
Resumiendo mucho: hemos entrenado un transformador de reducción de escala meteorológica para el conjunto de datos de reanálisis de última generación, ERA5, en la zona mediterránea. Lo hemos llamado ConvSwin2SR y lo hemos puesto a disposición de quien lo quiera usar en Hugging Face.
Además, como parte de nuestro compromiso con la comunidad de código abierto, presentamos el modelo ConvSwin2SR, un modelo puntero desarrollado durante el programa ECMWF Code 4 Earth por un equipo de investigadores de Predictia y del Instituto de Física de Cantabria en colaboración con ECMWF.
La motivación que nos llevó a desarrollar ConvSwin2SR es sencilla: hacen falta modelos de aprendizaje profundo que se puedan ejecutar rápidamente (a una fracción del coste de ejecutar un reanálisis regional) para reducir el coste de acceso a conjuntos de datos de reanálisis de alta resolución. Actualmente, el ECMWF ofrece el conjunto de datos ERA5 casi en tiempo real, pero su resolución espacial puede ser demasiado baja para muchos de sus usos. Por lo tanto, los organismos públicos, empresas y otras organizaciones pueden beneficiarse de ConvSwin2SR a la hora de tomar decisiones relacionadas con agricultura, energía, gestión de desastres y recursos hídricos o salud pública, entre otros campos.
Además, el modelo ConvSwin2SR puede utilizarse con proyecciones climáticas para obtener datos de alta resolución que puedan emplearse en estrategias de adaptación y mitigación del cambio climático.
Reducción de escala de los reanálisis
El problema que aquí se aborda se conoce como "superresolución” en el campo de la visión por ordenador, pero en meteorología se denomina “reducción de escala” ("downscaling"). Las técnicas de reducción de escala se agrupan de la siguiente manera:
- Dinámica: mediante el uso de modelos climáticos numéricos (también llamados “modelos climáticos regionales”) que se acoplan a las condiciones de frontera proporcionadas por modelos climáticos globales de menor resolución.
- Estadística: representa el uso de técnicas estadísticas para encontrar relaciones entre las variables climáticas a gran escala y las condiciones a pequeña escala. Este enfoque está estrechamente relacionado con el concepto de superresolución en visión por ordenador.
Nuestro trabajo consiste en explorar las técnicas más punteras en el campo de la visión por ordenador para la reducción de escala estadística del reanálisis europeo.
Por un lado, se toma ERA5 como conjunto de datos de entrada. ERA5 es la quinta generación de reanálisis del ECMWF que proporciona información climática y meteorológica desde 1940 hasta la actualidad. El Servicio de Cambio Climático de Copernicus (C3S) publica las simulaciones de ERA5 con cinco días de retraso.
El C3S define el reanálisis como un método científico cuyo objetivo es estimar las condiciones meteorológicas de cada día a lo largo de un periodo temporal con la mayor precisión posible. Se basa en multitud de observaciones meteorológicas pasadas de todo el planeta y en distintos momentos, integradas en un modelo informático meteorológico actual. Los resultados del reanálisis se denominan “productos reticulares”. En el ERA5, la resolución espacial es de unos 30x30 km, lo que significa que cualquier valor puntual es una representación del entorno combinado de todos los estados de la atmósfera dentro de ese cuadrante de 30x30 km.
Por otra parte, CERRA es un reanálisis de área limitada que cubre Europa con una mayor resolución espacial (5,5 km). CERRA se basa en la asimilación de datos HARMONIE-ALADIN y también lo publica C3S. CERRA cubre el periodo comprendido entre 1984 y 2021, por lo que en el momento de desarrollar nuestro modelo no se actualizaba de manera continua.
Entrenaremos a ConvSwin2SR para tomar la temperatura de ERA5 como datos de entrada mientras que el campo de CERRA se utilizará como objetivo. ConvSwin2SR pretende emular el reanálisis regional de CERRA y permite disponer de un campo de temperatura de 5 km actualizado constantemente.
Fuentes de datos
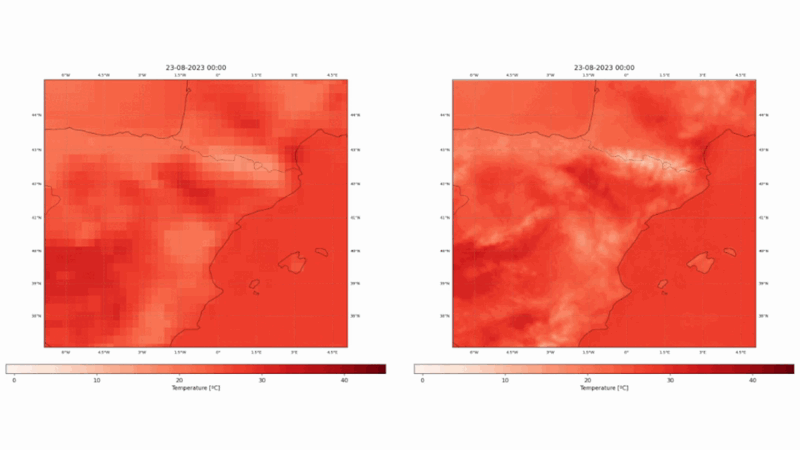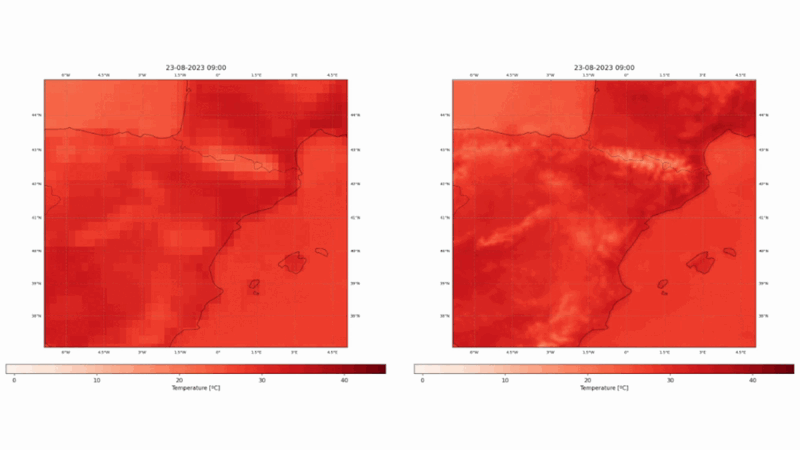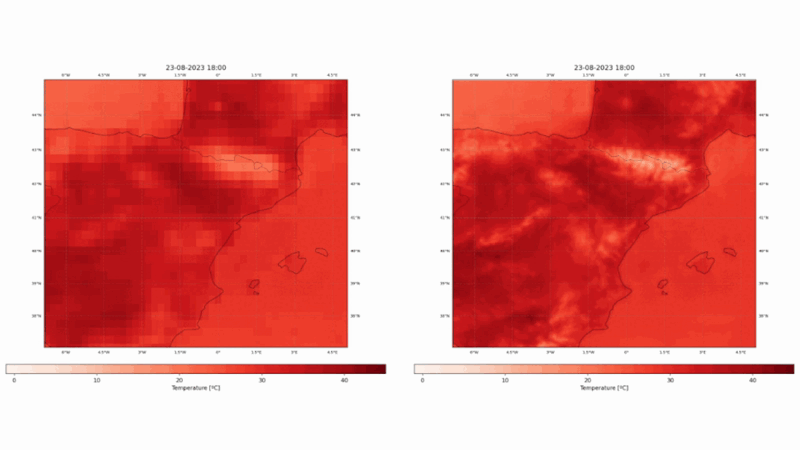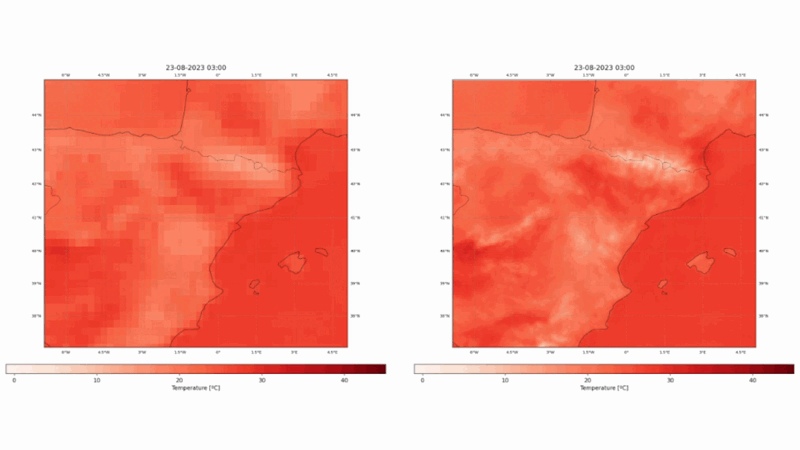
Este proyecto ha utilizado los dos reanálisis europeos, ERA5 y CERRA, para diseñar, entrenar y validar modelos estadísticos de reducción de escala con técnicas vanguardistas de aprendizaje profundo, como transformadores de visión o modelos de difusión. Los modelos toman como entrada los campos del ERA5 e intentan producir campos similares a los del CERRA. Hemos elegido una región mediterránea fija, como se puede apreciar en la figura 1. El espacio seleccionado abarca muchos ecosistemas diversos, como montañas, lagos, mares, islas y ríos, entre otros.

ERA5
Según la definición del C3S, "ERA5 es la quinta generación de reanálisis del ECMWF del clima y el tiempo en todo el mundo" desde 1940 hasta la actualidad. "ERA5 proporciona estimaciones horarias para un gran número de variables meteorológicas en distintos niveles de presión y en la superficie. Un subconjunto de 10 miembros muestrean la estimación de la incertidumbre a intervalos de tres horas. La media y la dispersión del conjunto se han calculado previamente para mayor comodidad. Estas estimaciones de incertidumbre están estrechamente relacionadas con el contenido informativo del sistema de observación disponible, que ha evolucionado de manera considerable con el tiempo. También indican las zonas sensibles dependientes del flujo. De cara a facilitar muchas aplicaciones climáticas, también se han calculado con anterioridad las medias mensuales, aunque las medias mensuales no están disponibles para la media y la dispersión del conjunto", explica el C3S.
Las mallas de entrada están estructuradas como tensores 4D con dimensiones de: (tamaño del lote, 1, 60, 44)
…de las que 60 y 44 son el número de puntos de la malla a lo largo de los ejes de longitud y latitud, respectivamente. A nivel geográfico, los datos del ERA5 abarcan una región que se extiende desde el punto más al oeste, a -8,35 de longitud, hasta el punto situado más al este, a 6,6 de longitud, y desde el punto situado más al norte, a 46,45 de latitud, hasta el punto situado más al sur, a 35,50 de latitud.
CERRA
El sistema CERRA se basa en el sistema de asimilación de datos HARMONIE-ALADIN, desarrollado y utilizado en el marco del consorcio ACCORD. Se ha desarrollado y optimizado para toda la región europea con las zonas marítimas circundantes con una resolución horizontal de 5,5 km y 106 niveles verticales. El sistema usa condiciones de límites laterales obtenidas del reanálisis global ERA5. Además, las grandes escalas del sistema regional están limitadas por los datos del reanálisis global.
Se representan como tensores 4D con dimensiones de: (tamaño del lote, 1, 240, 160)
…lo que indica una resolución de rejilla más alta en comparación con las rejillas de entrada. Aquí, 240 y 160 son el número de puntos de cuadrícula a lo largo de los ejes de longitud y latitud, respectivamente. La cobertura geográfica de estas cuadrículas de alta resolución se extiende desde el punto occidental -6,85 de longitud, hasta un punto oriental 5,1 de longitud, y desde el punto más septentrional 44,95 de latitud, hasta el punto más meridional 37 de latitud.
Tratamiento de los datos
El preprocesamiento de los conjuntos de datos climáticos ERA5 y CERRA, extraídos del Climate Data Store, es un paso crítico antes de su utilización en los modelos de entrenamiento. Esta sección define los pasos de preprocesamiento realizados para homogeneizar estos conjuntos de datos en un formato común. Los pasos incluyen la normalización de unidades, la rectificación del sistema de coordenadas y la interpolación de cuadrículas.
La metodología empleada en cada paso se analiza exhaustivamente en los párrafos siguientes:
- Normalización de unidades: el paso preliminar en el proceso de preprocesado fue la normalización de las unidades en ambos conjuntos de datos. Resultaba imprescindible para garantizar un sistema de unidades uniforme que facilitara una integración perfecta de los conjuntos de datos en etapas posteriores.
- Rectificación del sistema de coordenadas: el sistema de coordenadas de los conjuntos de datos se rectificó para garantizar una representación coherente de la información geográfica. En concreto, las coordenadas y dimensiones se renombraron a un formato normalizado con longitud (lon) y latitud (lat) como nombres designados. Los valores de longitud se ajustaron para que oscilaran entre -180 y 180 en lugar del rango inicial de 0 a 360, mientras que los valores de latitud se ordenaron en orden ascendente, alineándose así con los sistemas de coordenadas geográficas convencionales.
- Interpolación de rejillas: el conjunto de datos ERA5 está estructurado en una malla regular con una resolución espacial de 0,25º, mientras que el conjunto de datos CERRA lo está en una curvilínea con una proyección de Lambert de mayor resolución espacial (0,05º). Para superar esta disparidad entre los dos reanálisis, se lleva a cabo un procedimiento de interpolación sobre el conjunto de datos de CERRA. Este paso es crucial para alinear las dos representaciones espaciales en un formato común, la rejilla regular (con diferentes resoluciones espaciales) de ERA5, garantizando de este modo la coherencia en la representación espacial.
Esquema de normalización
Durante y después de ECMWF Code 4 Earth, exploramos todas las siguientes técnicas de normalización:
Con climatologías históricas
Consiste en calcular las climatologías históricas durante el periodo de entrenamiento para cada región (píxel o dominio), y normalizar con respecto a ello. En nuestro caso, se tuvieron en cuenta las climatologías mensuales, pero también podría desagregarse por la hora del día, por ejemplo.
- Por píxeles: en este caso, la climatología se calcula para cada píxel del campo meteorológico. A continuación, cada píxel se normaliza con sus propias estadísticas climatológicas.
- Por dominio: para este caso, las estadísticas de la climatología se calculan para toda la región de estudio. Una vez calculadas las estadísticas, se abre la posibilidad de dos esquemas distintos de normalización:
- Independiente: se refiere a normalizar ERA5 y CERRA independientemente, cada uno con sus propias estadísticas.
- Dependiente: se refiere a utilizar sólo las estadísticas de climatología de ERA5 para normalizar simultáneamente ERA5 y CERRA.
El enfoque dependiente no es viable para el esquema por píxeles, porque no hay correspondencia directa entre los píxeles de los parches de entrada y de salida.
Sin información anterior
Esto corresponde a normalizar cada muestra de manera independiente por la media y la desviación estándar del campo de ERA5. Esto se conoce en la comunidad del aprendizaje automático como “normalización por muestra”. En este caso, tenemos que utilizar únicamente las estadísticas de distribución de las entradas, ya que las salidas no estarán disponibles durante la inferencia, pero en nuestro caso son posibles dos variaciones diferentes:
- Utilizar las estadísticas de ERA5, teniendo en cuenta que cubre un área más amplia que CERRA.
- Usar las estadísticas de ERA5 interpolado de manera bicúbica, que representan la misma zona que CERRA.
La diferencia entre estos dos enfoques es que las variables predictoras abarcan un área mayor y, por tanto, su distribución varía más. Por lo tanto, el segundo enfoque parece más correcto, ya que la distribución del área reducida sería más similar a la distribución de salida.
Métodos
Durante el ECMWF Code 4 Earth se exploraron varios enfoques estadísticos de reducción de escala. En este post, nos centramos en los transformadores de visión, pero también desarrollamos modelos de difusión, U-Nets y técnicas de interpolación estándar.
Arquitectura del modelo
El diseño de nuestro modelo está profundamente arraigado en la arquitectura Swin v2 adaptada de manera específica para tareas de súper resolución. La biblioteca transformers se utiliza para simplificar el diseño del modelo.
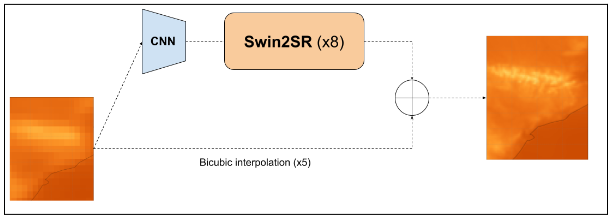
El transformers.Swin2SRModel es fundamental para nuestro modelo. Este componente amplía la resolución espacial de sus entradas por un factor de 8.
Como Swin2SRModel sólo admite relaciones de aumento de escala que sean potencias de 2, y la relación real de aumento de escala es de ~5, se incluye una red neuronal convolucional como módulo de preprocesamiento. Este módulo convierte las entradas en un mapa de características (20, 30) que puede introducirse en el modelo Swin2SRModel para que coincida con la forma de salida de la región (160, 240).
El objetivo subyacente de ConvSwin2SR es corregir los errores de la interpolación bicúbica en ERA5.
Tamaño del modelo
Los parámetros específicos de esta red están disponibles en config.json, y corresponden al aprendizaje profundo de 12.383.377 variables. Aunque se utilizan arquitecturas de modelo más ligeras, desde el parámetro 100.000 hasta el 120 millones, el mejor resultado en términos de valores de pérdida de validación corresponde a la arquitectura presentada, con 6 bloques de profundidad 6. La dimensión de las capas de incrustación en cada bloque es de 180. Además, el tamaño del parche se fija en un solo píxel y el tamaño de la ventana se establece en un divisor común de la longitud de ambas dimensiones de entrada (cinco, en este caso).
Función de pérdida
El modelo ConvSwin2SR optimiza sus parámetros utilizando una función de pérdida compuesta que agrega múltiples términos de pérdida L1 para mejorar su precisión predictiva y su robustez:
- Pérdida de predicciones primarias: Este término calcula la pérdida L1 entre las predicciones del modelo primario y los valores de referencia. Garantiza que las salidas del transformador coincidan con la realidad.
- Pérdida de predicciones con muestreo reducido: Este término calcula la pérdida L1 entre las versiones con muestreo reducido de las predicciones y los valores de referencia. Al incorporar este término, se incentiva al modelo a preservar las relaciones subyacentes entre ambas resoluciones espaciales. Las referencias y las predicciones se amplían mediante la agrupación de promedios en un factor x5 para ajustarse a la resolución de la fuente. Aunque este término de pérdida podría calcularse (técnicamente) con respecto a la muestra de baja resolución, se tienen en cuenta los valores de referencia ampliados, ya que la agrupación de medias utilizada para la ampliación no representa la verdadera relación entre los dos conjuntos de datos.
- Pérdida de predicciones borrosas: Para garantizar la solidez del modelo frente a pequeñas perturbaciones y ruido, este término evalúa la pérdida L1 entre las versiones borrosas de las predicciones y las referencias. Sirve para que el modelo produzca predicciones que mantengan la precisión incluso bajo ligeras modificaciones en la representación de los datos. Por otro lado, puede suavizar demasiado el campo de predicción, por lo que su uso debe estudiarse detenidamente antes de incluirlo en el modelo. Para producir los valores borrosos, se aplica un kernel gaussiano de tamaño 5.
Detalles del entrenamiento
El modelo ConvSwin2SR se entrena a lo largo de 100 épocas, con una duración total de 3.648 días y un tamaño de lote de 2. Dado el tamaño de la red y los datos de entrada, el número de muestras del lote está limitado por la memoria de los equipos utilizados. Dado que el uso de lotes pequeños puede afectar al entrenamiento, hemos acumulado los gradientes de 4 lotes antes de actualizar los pesos del modelo. Con eso conseguimos varias cosas:
- Estabilizar el entrenamiento: Esta técnica suaviza los gradientes al promediarlos entre varios lotes, facilitando la convergencia en la primera fase del entrenamiento de redes profundas de gran tamaño. En estos casos, es común ver que el modelo diverge rápidamente al principio del entrenamiento o que oscila sin converger a un mínimo.
- Mayor robustez. Agregar los gradientes de la función de pérdida sobre varios lotes permite tener una mejor estimación del gradiente real, y por lo tanto, aprender de manera más representativa las relaciones subyacentes en los datos.
El optimizador Adam utiliza una tasa de aprendizaje que comienza en 0,0001 y disminuye siguiendo los valores de la función coseno. Además, la tasa de aprendizaje del optimizador tiene una fase de calentamiento de 500 pasos en la que la tasa de aprendizaje aumenta de manera lineal de 0 a 0,0001. El objetivo del calentamiento es evitar que los gradientes del modelo exploten en los primeros pasos de la fase de entrenamiento, y permitir que el modelo converja más rápidamente cuando el entrenamiento se estabilice.
La división temporal del conjunto de datos está estructurada para optimizar el entrenamiento del modelo y la posterior validación por épocas. La duración del entrenamiento abarca 29 años, desde enero de 1985 hasta diciembre de 2013. A continuación se inicia la fase de validación, que abarca el periodo comprendido entre enero de 2014 y diciembre de 2017. Este intervalo de 4 años se dedica exclusivamente a evaluar la aptitud del modelo sobre datos a los que no ha estado expuesto durante el entrenamiento. Esta separación garantiza la solidez del modelo y su capacidad para realizar predicciones fiables.
Además de los términos de pérdida, se calculan algunas métricas de interés durante el proceso del entrenamiento, como la tasa de mejora con respecto al método de referencia (la interpolación bicúbica) y el sesgo relativo o el cociente entre varianzas de las predicciones y los valores de referencia. Se despliega un panel de control TensorBoard, con los valores de la función de pérdida y las métricas en los conjuntos de datos de entrenamiento y validación a lo largo de las 100 épocas.
El modelo ConvSwin2SR demuestra una velocidad de inferencia encomiable. En concreto, cuando se le encarga la reducción de escala de 248 muestras, lo que equivale a todo un mes de muestras ERA5 en intervalos de 3 horas, el modelo completa la operación en 21 segundos. Este nivel de eficiencia se observa en un entorno informático local equipado con 16 GB de RAM y 4 GB de memoria GPU.
Resultados
Conjunto de datos de prueba
Las muestras de datos de prueba corresponden al trienio comprendido entre 2018 y 2020. Este segmento es crucial para evaluar la aplicabilidad del modelo en el mundo real y su rendimiento en los puntos de datos más recientes, garantizando su relevancia y fiabilidad en escenarios actuales y futuros.
Evaluación del modelo
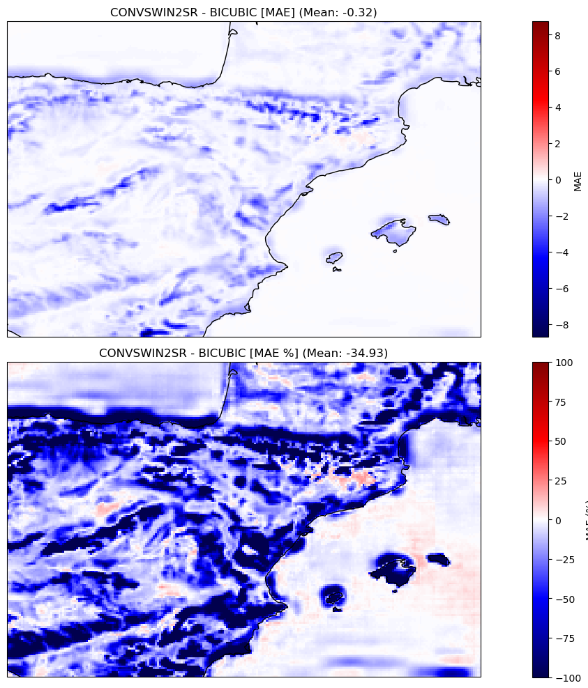
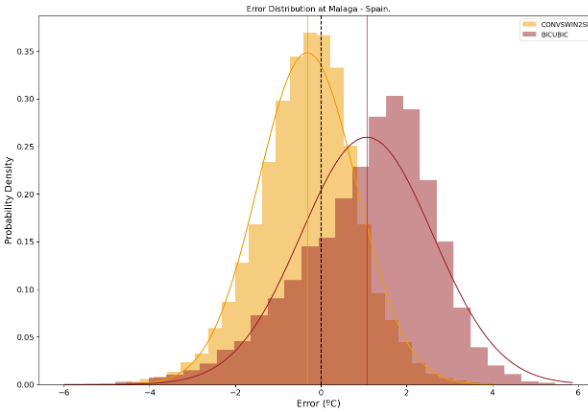
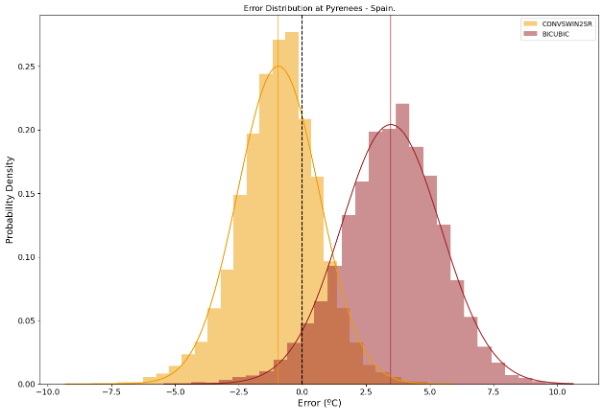
En nuestra evaluación, el modelo propuesto mostró una mejora significativa con respecto a la línea de base establecida, que emplea la interpolación bicúbica para la misma tarea. En concreto, nuestro modelo logró una notable reducción del 34,93% en el error absoluto medio, una métrica indicativa de la magnitud media de los errores entre los valores predichos y los reales (véase la Figura 3), lo que corresponde a una reducción de 0,32ºC con respecto a la línea de base del error absoluto medio. Además, se produjo una mejora cercana al 30% en el error cuadrático medio. Se observan patrones espaciales similares en ambas métricas, donde la mayor mejora corresponde a las zonas montañosas, así como a la línea de costa.
Los resultados de ConvSwin2SR no sólo subrayan su capacidad para mejorar las predicciones, sino que también arrojan unos resultados increíbles en lugares de interés, por su dificultad, como las zonas costeras, las zonas montañosas o las islas (véanse las figuras 4 y 5).
Recursos computacionales
El aprovechamiento de las GPU en iniciativas de aprendizaje profundo amplifica enormemente el ritmo de entrenamiento e inferencia de los modelos. Esta ventaja computacional disminuye la duración total del cálculo al tiempo que nos capacita para manejar con soltura tareas complejas y conjuntos de datos de gran tamaño.
Proveedores de recursos
Tenemos una deuda de gratitud con varios socios, cuya inestimable contribución y apoyo han sido clave para que este proyecto fructificara. Sus importantes aportaciones han impulsado de manera inmensa nuestros avances en investigación y desarrollo.
AI4EOSC
* AI4EOSC son las siglas de "Artificial Intelligence for the European Open Science Cloud". La European Open Science Cloud (EOSC) es una iniciativa de la Unión Europea cuyo objetivo es crear un entorno descentralizado de datos y servicios de investigación. AI4EOSC es un proyecto o iniciativa específica dentro del marco de la EOSC que se centra en la integración y aplicación de tecnologías de inteligencia artificial en el contexto de la ciencia abierta. ConvSwin2SR figurará en breve entre los productos gratuitos disponibles de la plataforma de AI4EOSC.
* European Weather Cloud: es la plataforma de colaboración basada en una nube para el desarrollo y las operaciones de aplicaciones meteorológicas en Europa. Los servicios prestados abarcan desde la entrega de datos y productos de previsión meteorológica hasta el suministro de recursos informáticos y de almacenamiento, asistencia y asesoramiento de expertos.
Hardware
Para nuestro proyecto hemos desplegado dos máquinas virtuales, cada una con una tarjeta gráfica dedicada. Una de ellas está equipada con una tarjeta gráfica de 16 GB, mientras que la otra dispone de una tarjeta gráfica más potente, de 20 GB. Esta configuración de recursos nos permite gestionar con eficacia una amplia gama de tareas de cálculo, desde el procesamiento de datos hasta el entrenamiento y muestreo de modelos, y en última instancia impulsa la ejecución satisfactoria de nuestro proyecto.
No se trata sólo de disponer más rápidamente de un modelo operativo eficiente: la principal ventaja es probar rápidamente nuestras soluciones. Por tanto, tener la posibilidad de cometer errores en una fase más temprana y obtener mejores modelos operativos.
Software
El código utilizado para descargar y preparar los datos, y entrenar y evaluar este modelo está disponible gratis a través del repositorio GitHub ECMWFCode4Earth/DeepR alojado por la organización ECMWF Code 4 Earth.
Más información
- Conde, M. V., Choi, U. J., Burchi, M., & Timofte, R. (octubre 2022). Swin2SR: Swinv2 transformer for compressed image super-resolution and restoration. In European Conference on Computer Vision (pp. 669-687). Cham: Springer Nature Switzerland.
- Hersbach, H, Bell, B, Berrisford, P, et al. The ERA5 global reanalysis. Q J R Meteorol Soc. 2020; 146: 1999–2049. https://doi.org/10.1002/qj.3803.
- Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Liu, Z., Hu, H., Lin, Y., Yao, Z., Xie, Z., Wei, Y.,... & Guo, B. (2022). Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 12009-12019).
- Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A.,... & Rush, A. M. (octubre 2020). Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations (pp. 38-45).
Si quieres saber más, no dudes en ponerte en contacto con nuestro equipo en predictia@predictia.es